运维痛哭流涕:老板,资源共享就是难!加机器还得被嫌弃?
小张:老板!Hadoop 集群需要增加3台机器,Spark集群要增加2台机器,最后合算下来平台服务部门需要增加10万块钱预算~
老板:你把现有统一的资源拿出来看看,告诉我整体利用率是多少?
此时,小张统计下来,Spark不仅不缺存储,还余出来不少;再看计算资源,Spark集群倒是需要不少,但是Hadoop不咋用啊……如此一来,将这些资源统起来看,哎!存储和计算资源都不缺……
老板:你看资源充足,怎么还要买机器?你咋老想着花钱呢?
小张对自己的表达能力,深深地陷入了自我怀疑中。
小张没有放弃,并试图让老板理解大数据平台各集群的工作情况。
小张:老板!Hadoop、Spark、Kafka……各个系统各自为战,Hadoop存储资源不足就得给它补上存储资源,Spark集群计算资源不足,就得给它补上计算资源。即使Spark集群有空闲的存储资源,也无法为Hadoop集群所用;Hadoop集群有空闲的计算资源,也无法给Spark集群所用,每个系统的资源都是无法和其他系统共享的。
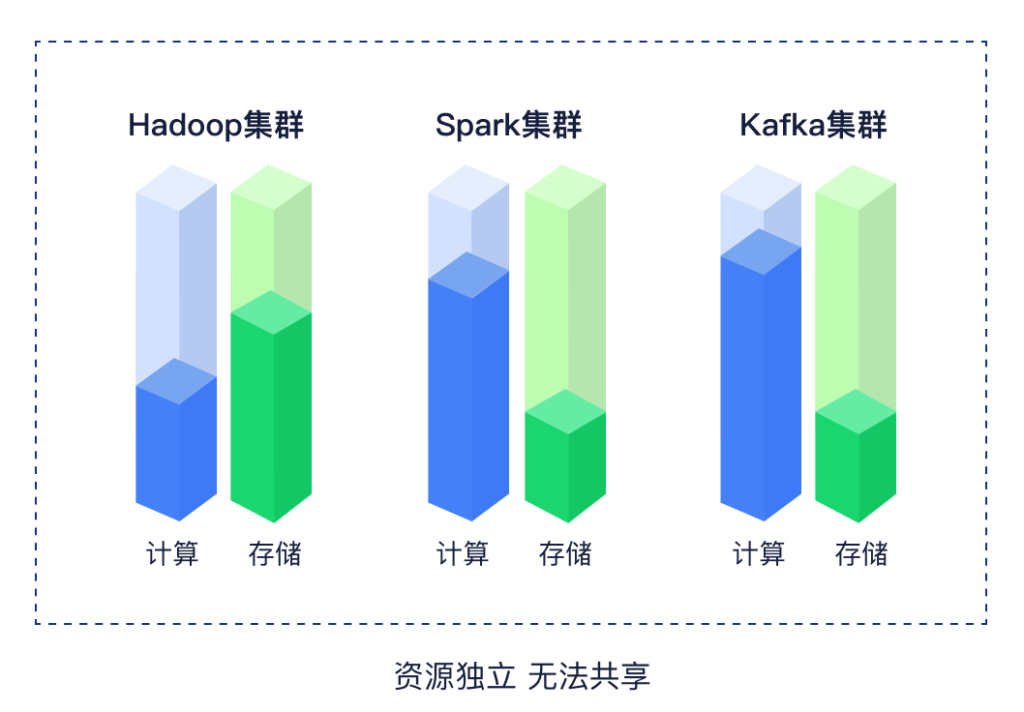
老板彻底被绕晕了,又想着要这些技术人员干嘛?解决不了问题,还总是要钱,瞬间火冒三丈。
你看小张和老板悲催的对话场景,相信不少运维人和老板们都感同身受。但是,这能怪老板不懂技术吗?能怪运维人员解释的不清楚吗?当然不能,他们也深受其害,罪魁祸首就是传统大数据平台。
传统模式的大数据平台,因为担心各组件之间互相影响,谁都不敢占用上面的节点发布数据应用。
那么,传统大数据平台有什么痛点?因为传统大数据平台比如Hadoop、HBase、Hive每一个子系统都有自己的分布式管理机制以及安装流程,无法共享资源池,所以系统在运行的时候安装和运维比较复杂,工作量非常大,迭代效率低。此外,随着业务系统逐渐向云原生体系迁移,很多企业需要同时在业务系统使用的Kubernetes集群之外单独运行一个Hadoop集群,数据需要在各个不同集群中来回拷贝,没法形成统一的体系,资源使用效率非常低。

解决资源共享难题,云原生大数据平台就可以轻松做到。
为了避免系统中各个组件各自为战,无法形成统一体系的局面,将Hadoop、Spark、Kafka等一套组件构建在统一的数字底座上,进行统一管理,从而达到资源共享,这就是我们常听说的云原生大数据平台的理念。
如此看来,解决传统大数据平台的痛点,解决方案就是Data On Kubernetes,核心的变化就是把大数据组件和大数据应用的发布与运维,用Kubernetes(K8s)来标准化。
在K8s集群上,大数据组件与各种应用都以容器化云原生的方式发布到K8s集群上,其上的计算资源、存储资源可以混合编排。因为以云原生的架构发布方式,使得数据云原生、数据平台云原生、应用云原生,都可以混跑在一套K8s集群上,统一资源调度,资源得以充分利用。
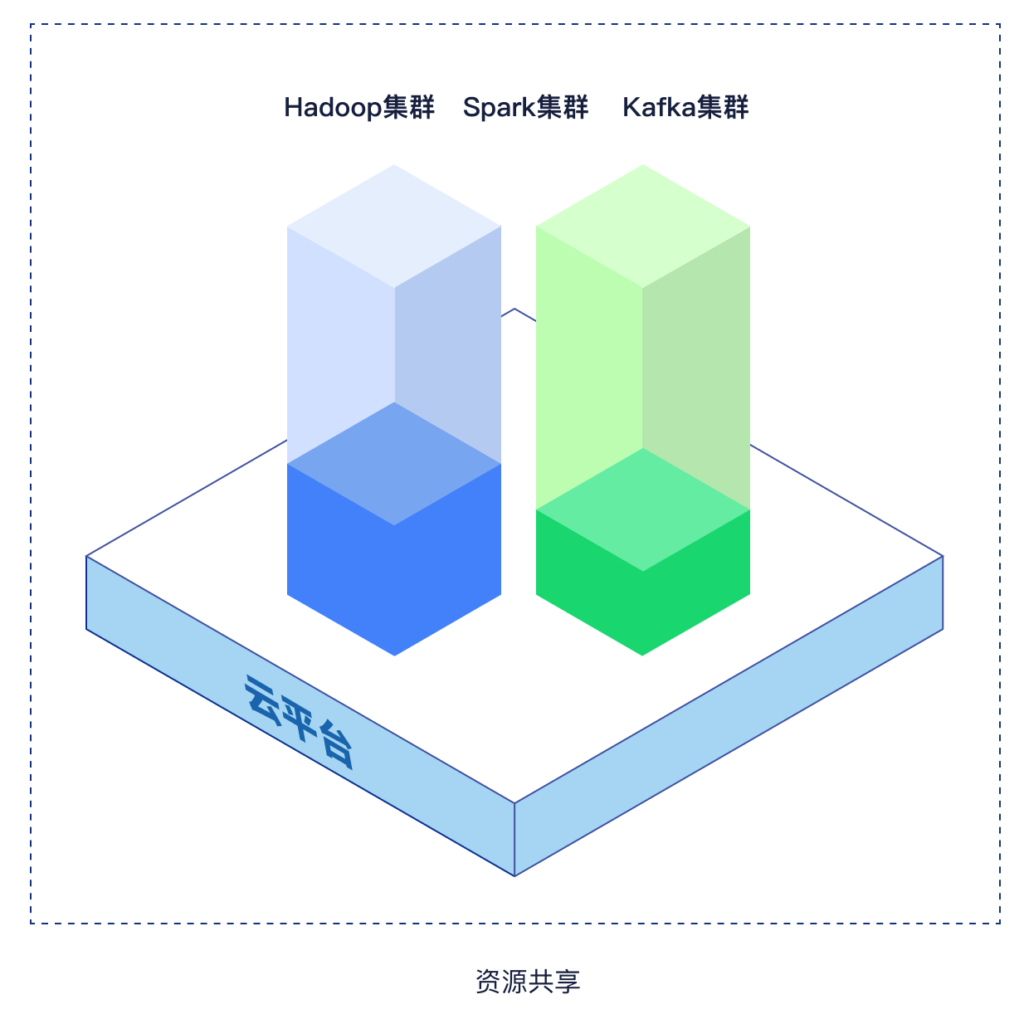
那么,作为运维人员来说,资源哪里充足哪里短缺就一目了然了,因为整体资源利用率可以在K8s集群中统一管理和监测。
换句话说,使用云原生大数据平台后,所有节点部署在K8s集群上,原来独占的节点进行了共享,存储节点多出来的计算资源,可以给其他CPU-intensive的应用使用;计算节点多出来的存储资源也可以给其他IO-intensive的应用使用。资源合理调度后,整体利用率自然得到提升。
作为运维体系来说,原来要和老板讲清楚各个组件是如何运行的,如果其中某些组件出了问题,想要运维这些组件时,还需要分别了解它们的日志是怎么采集的。
现在,将所有大数据组件放在一起,无需单独了解每个组件的运行情况,只需要看状态是否正常,如有异常平台会发出告警;并且所有日志都可以在统一的界面看到,组件报错有统一的自动告警,然后找到相应的人员再去解决。
云原生Kubernetes大数据平台KDP,将资源共享做到极致。
智领云KDP(Kubernetes Data Platform)作为市场上首个可完全在Kubernetes上部署的容器化云原生大数据平台,KDP就相当于一个中间管理层,类似于Windows的资源管理器,KDP就像是大数据组件的资源管理器,将所有大数据组件管理起来,让用户能够更加方便地使用,从而大大提升系统运行效率,降低运维成本。

具体来看,智领云KDP之所以被成为“真正的”云原生大数据平台,是因为KDP支持所有主流的开源大数据组件,比如HDFS、Hbase、Spark、Flink、Kafka等,企业可以根据自己的需要选用这些组件。智领云所做的一个重要工作是在Kubernetes和这些开源组件之间建立起了一个统一的中间层,打通各个组件的联系,实现各个组件统一的管理和调度。
这件事做起来并不容易,尤其是在大数据组件标准化、统一资源管理,以及在Kubernetes环境中运行所有工作负载都是比较复杂的工作。比如要打通Hadoop、Hive、Spark之间的用户,在传统大数据平台上都需要复杂的手工配置,而现在,基于Kubernetes的KDP可以轻松打通用户管理,实现标准化,新组件只要一接入,就可以跟现有的系统方便地进行通讯。
具体而言,KDP能够标准化配置管理,即采用统一的Kubernetes文件配置方式,对大数据组件进行标准化的配置管理,简化大数据组件与Kubernetes集群的集成。
实现资源高效利用,集群资源作为一个可共享的资源池,实现实时、离线作业的混部,集群资源利用率相较于传统大数据平台的30%提升到60%;
弹性扩展,利用Kubernetes的弹性扩容技术,从容应对计算作业的性能瓶颈,实现计算资源及集群资源的动态扩容;
简化运维,基于Kubernetes标准的Operator操作方式,统一运维界面完成大数据组件的部署、升级、扩容、备份等操作,提升运维效率。
”市场是检验产品能力的最佳标准,智领云KDP推出以后,受到了市场头部客户的积极响应。未来通过KDP将会让更多的企业把数据平台迁移到Kubernetes,同时提供企业级安全、企业级的运营管理以及企业级的开发工具支持,实现KDP作为一个云原生数据底座的最终目标。

智领云是国内云原生大数据技术的创新领导者,为企业级客户提供以云原生大数据平台为底座的云原生DataOps产品系列,包括云原生数据集成开发平台和云原生数据资产运营平台。智领云通过产品及服务帮助企业搭建数据和AI中台,轻松打造业务数据能力闭环,建立数字化运营体系,并最终完成数据驱动的数字化转型。
智领云已经服务了能源、教育、医疗健康、物联网、金融等行业国内外多家知名企业,与多个合作伙伴在云原生生态领域中展开紧密的合作,充分利用各自的优势,共同为企业客户提供更有价值的云计算、大数据产品和技术服务。

留言
评论
${{item['author_name']}} 回复 ${{idToContentMap[item.parent] !== undefined ? idToContentMap[item.parent]['author_name'] : ''}}说 · ${{item.date.slice(0, 10)}} 回复
暂时还没有一条评论.