网易新闻点击量分析 – 操作指南
数据开发的目的是使用各种工具来分析数据,从数据中产生可指导行动的商业洞见,是从数据到价值的转换过程。在很多场景下,数据分析人员需要对海量的数据进行快速的分析,性能上要像在传统的数据仓库中运行查询语句一样,在几秒钟内得到数据分析的结果。
本README将以向导的形式,向大家展示一个典型的端到端大数据分析实例,包括数据采集、数据处理和数据分析及数据导出这几个步骤:
第一步,数据采集:在BDOS Online大数据平台,通过爬虫步骤爬取网易网页新闻,并将这些新闻数据存入HDFS(为方便用户体验,本系统将提供已爬取完成的一个样例数据供用户下载,用户可通过URL文件导入,导入到系统的HDFS;
第二步,数据处理:在Hive程序步骤中对新闻数据进行清洗并统计;
第三步,数据导出:再将统计后的数据导入到MySQL数据仓库中;
第四步,BI报表:使用Superset进行数据探索,将MySQL数据仓库中的统计数据以可视化的方式展示出来,分析网易新闻的受欢迎程度。(即将推出)
用户只需克隆本项目,通过几次简单的点击,即可完成端到端的数据分析场景。
完整文档下载链接
步骤介绍
1.克隆公共项目
用户登陆 BDOS Online 后,通过项目类型筛选公共项目,选择企业数仓-场景体验进行克隆
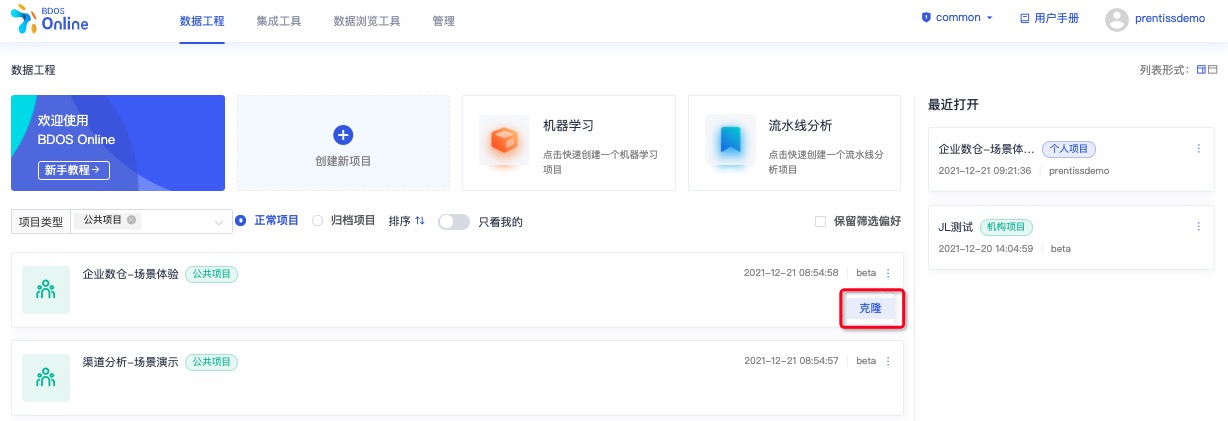
点击克隆,并自定义项目名称
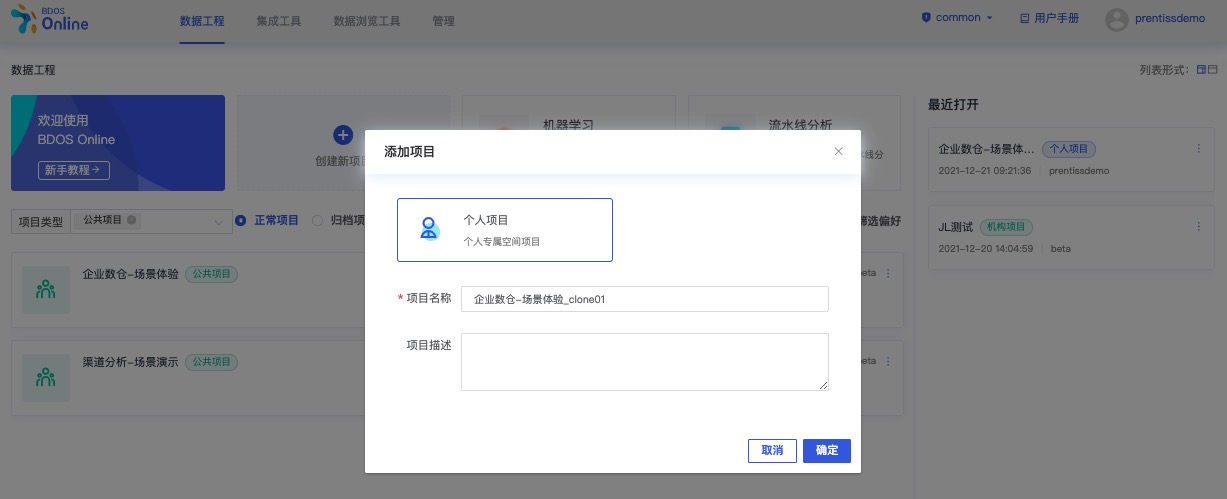
进入项目主页
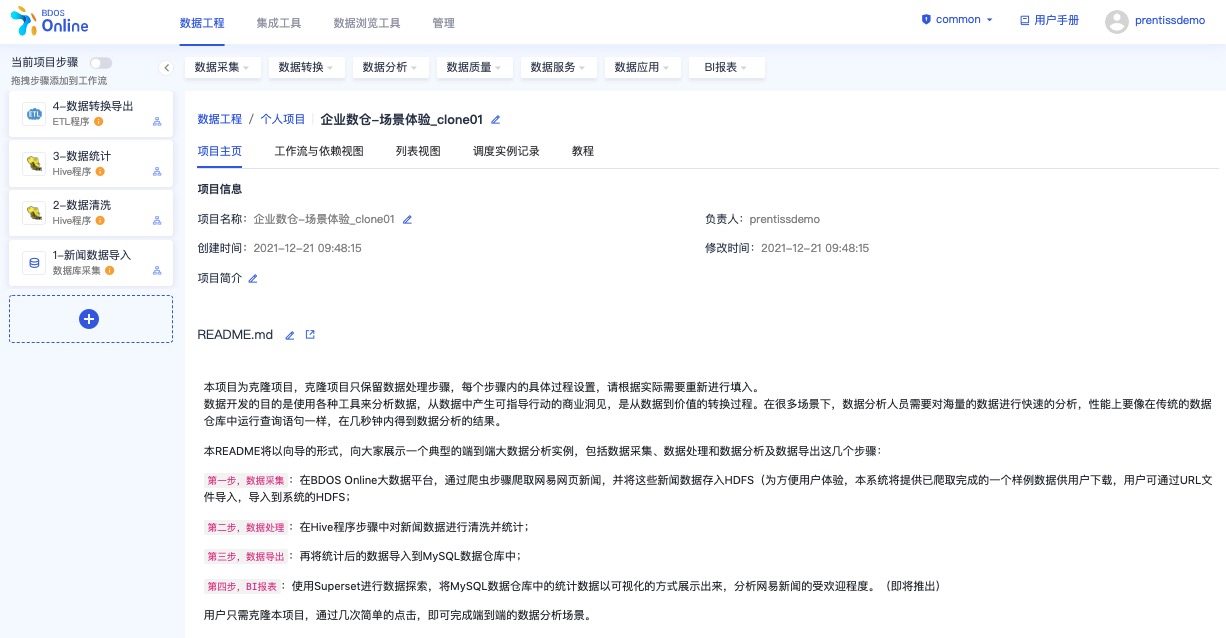
2. 启动项目步骤
2.1 数据库采集,新闻数据导入
克隆公共项目-企业数仓后,进入步骤1:新闻数据导入
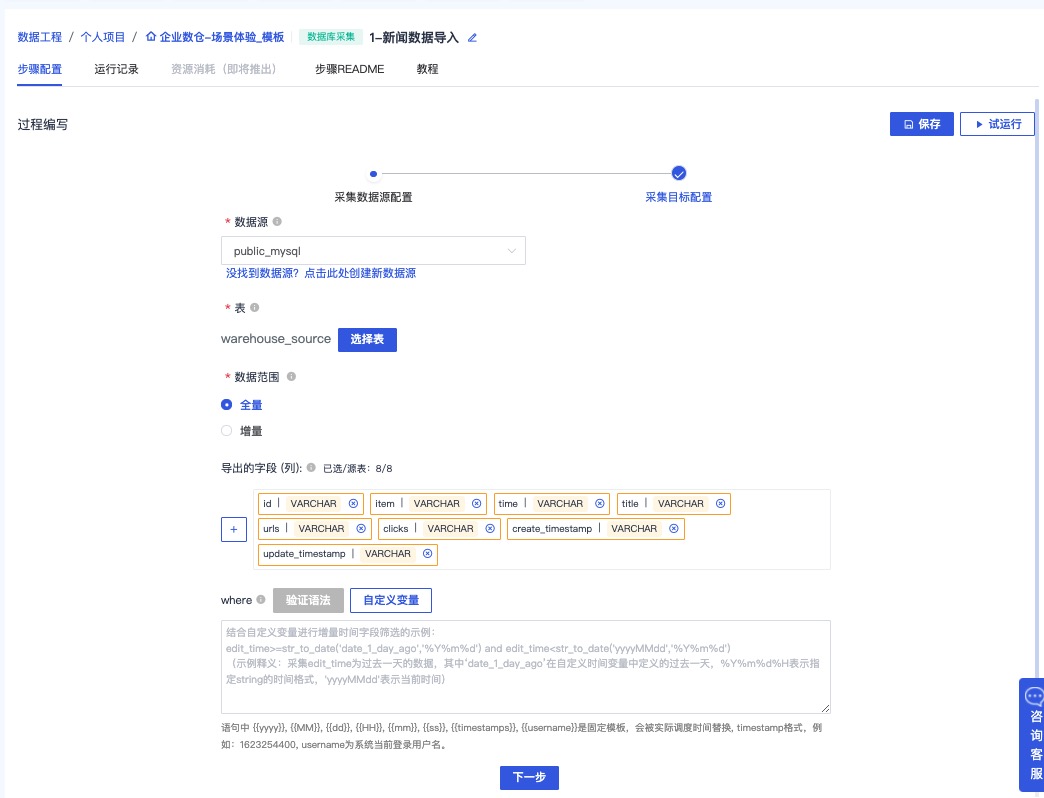
保持默认配置内容并点击下一步
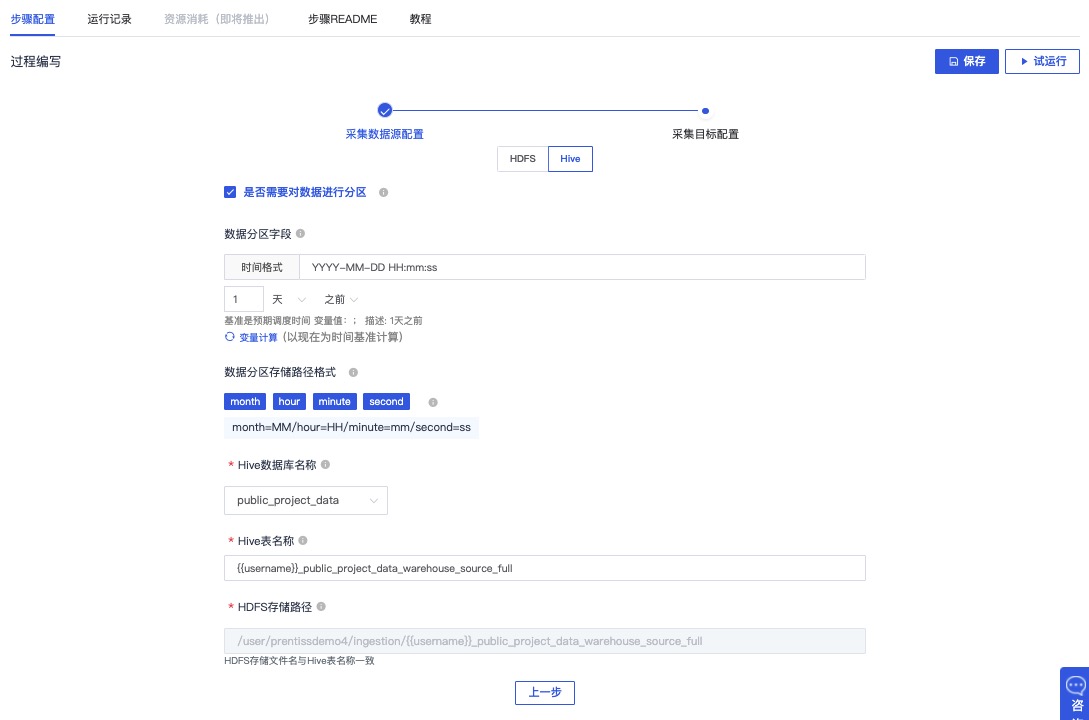
点击保存后,点击试运行
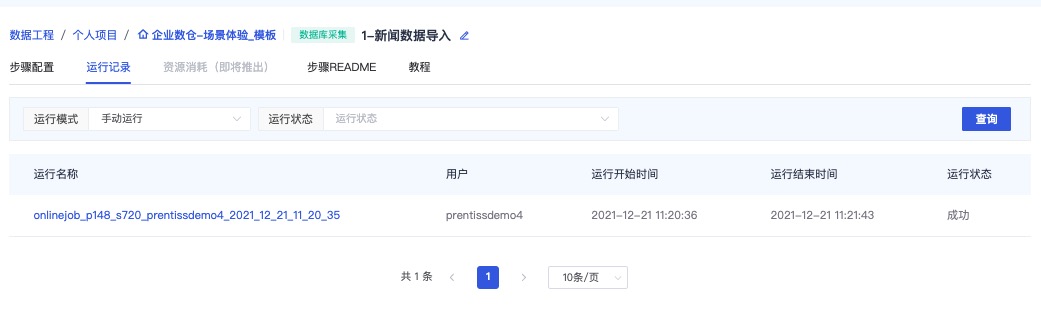
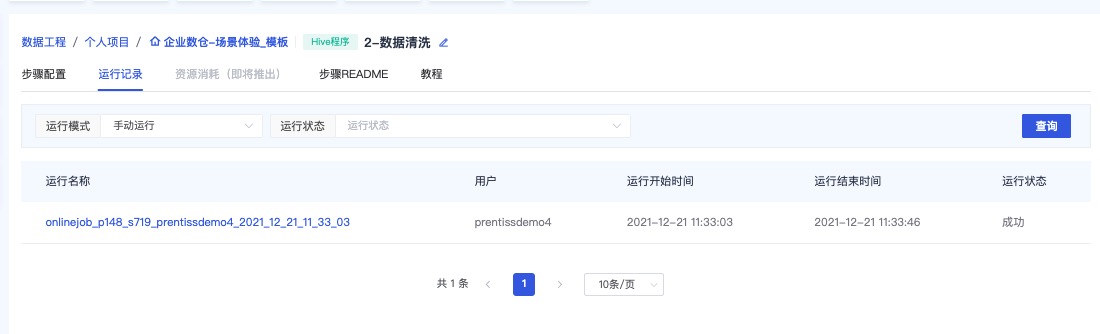
查看运行记录
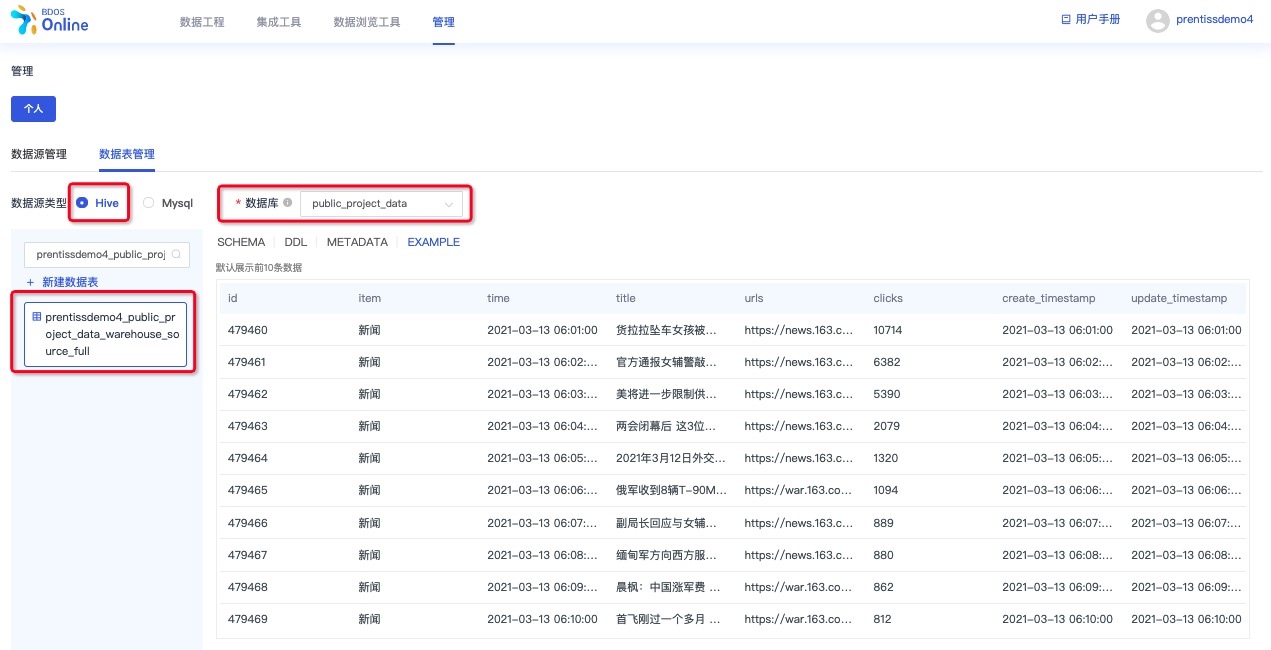
查看导入到公共 Hive 库的数据表
2.2 转数据分析–Hive程序步骤:数据清洗
通过本步骤对 Hive 库表数据进行清洗,并存入到新的 Hive 表。进入步骤2:数据清洗,点击进入编辑界面
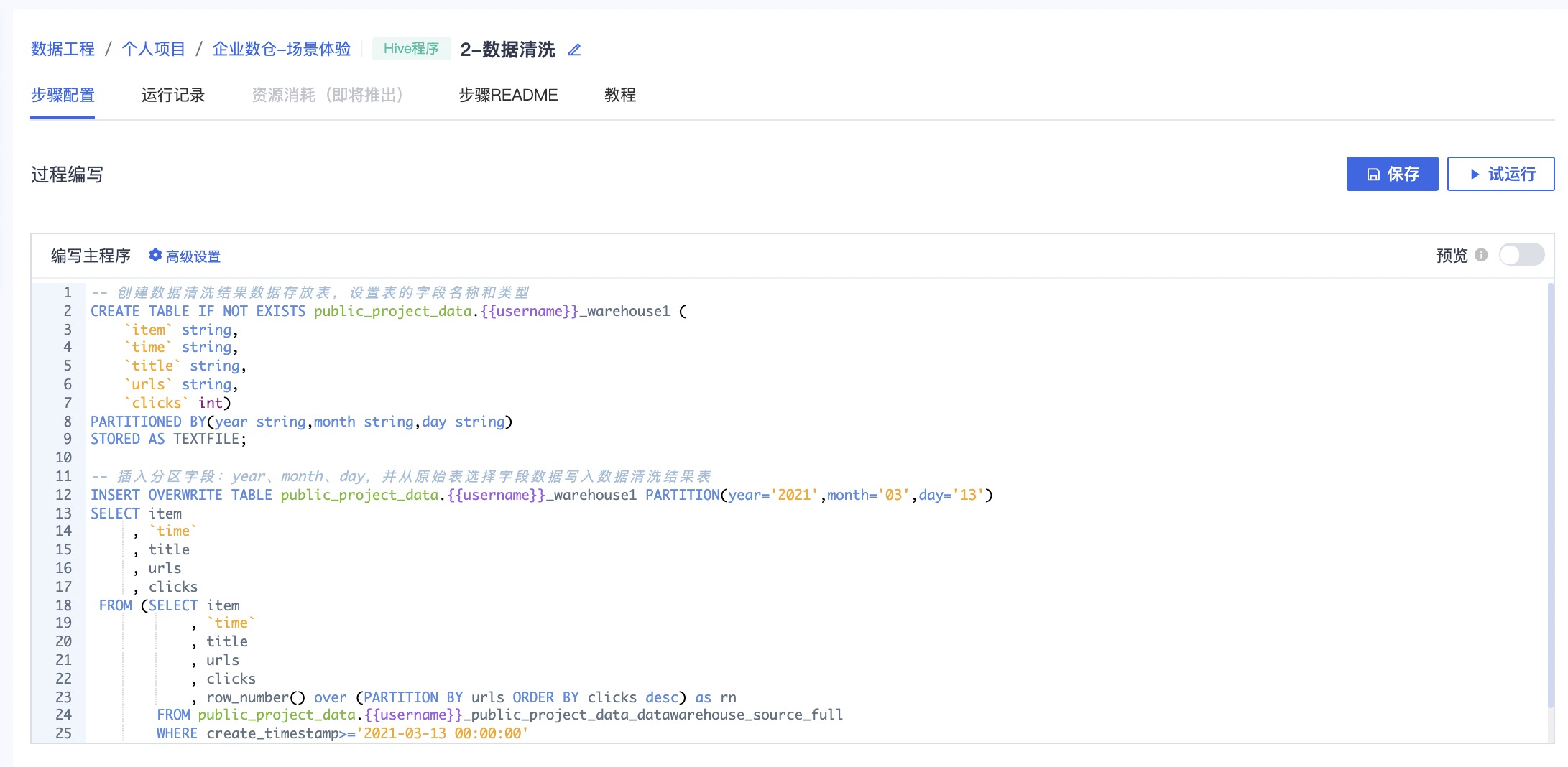
编写主程序
-- 创建数据清洗结果数据存放表,设置表的字段名称和类型
CREATE TABLE IF NOT EXISTS public_project_data.{{username}}_warehouse1 (
`item` string,
`time` string,
`title` string,
`urls` string,
`clicks` int)
PARTITIONED BY(year string,month string,day string)
STORED AS TEXTFILE;
-- 插入分区字段:year、month、day,并从原始表选择字段数据写入数据清洗结果表
INSERT OVERWRITE TABLE public_project_data.{{username}}_warehouse1 PARTITION(year='2021',month='03',day='13')
SELECT item
, `time`
, title
, urls
, clicks
FROM (SELECT item
, `time`
, title
, urls
, clicks
, row_number() over (PARTITION BY urls ORDER BY clicks desc) as rn
FROM public_project_data.{{username}}_public_project_data_datawarehouse_source_full
WHERE create_timestamp>='2021-03-13 00:00:00'
) t
WHERE t.rn=1
保持默认,点击保存后,点击试运行
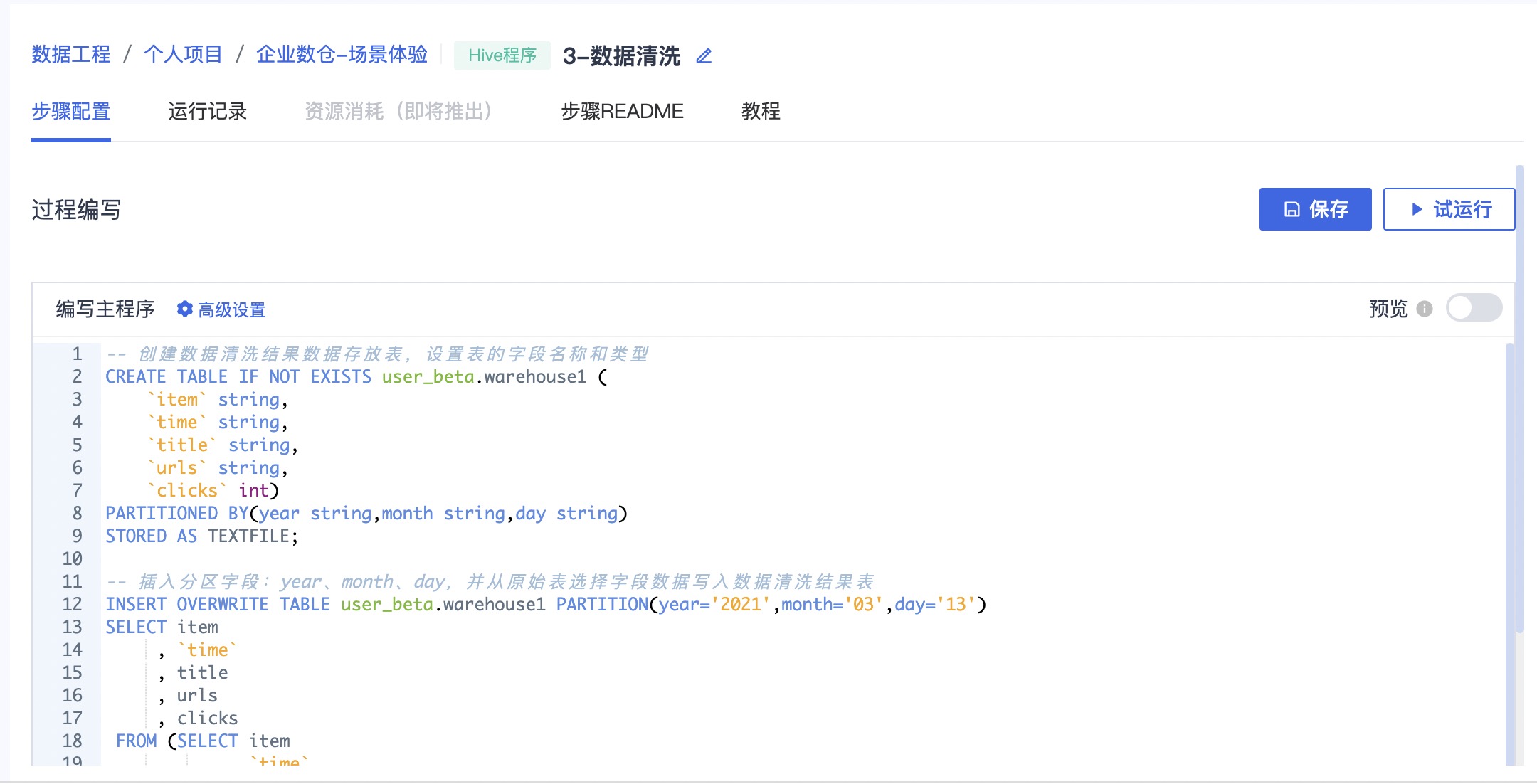
运行完成后,可以在运行记录中确认运行结果。
查看运行记录
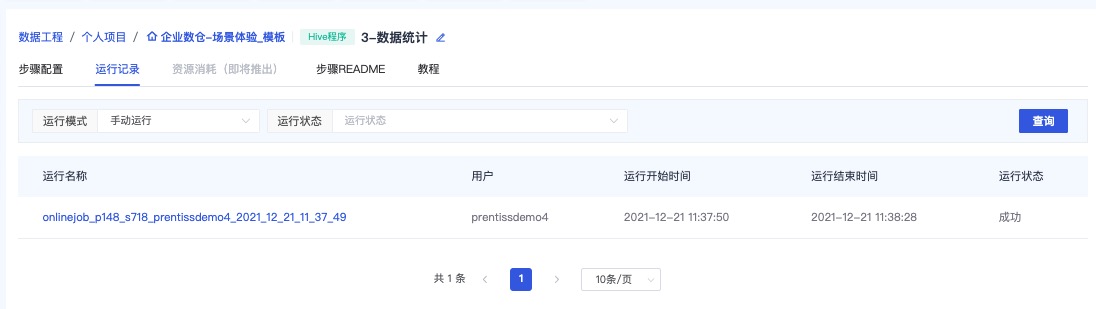
参考截图查看Hive程序运行记录,可点击运行名称查看日志详情
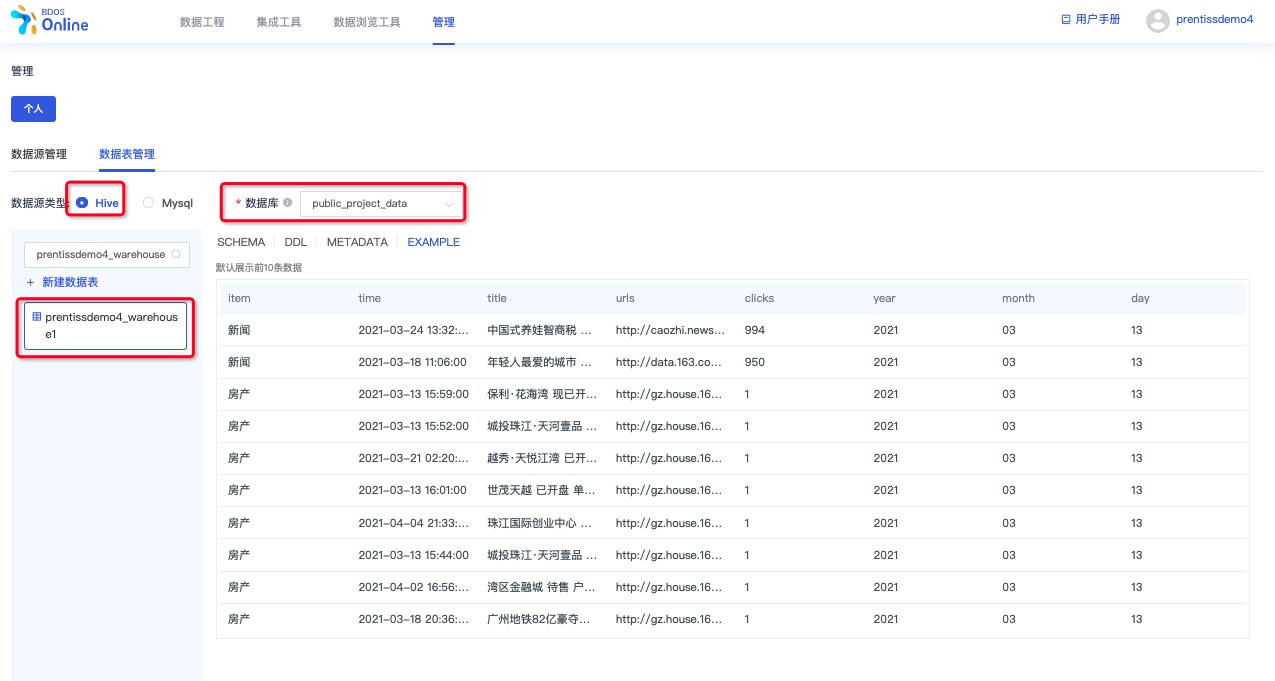
预览数据表
用户从【管理-个人-数据表管理】菜单进入,通过数据源类型和数据库筛选,可预览上一个步骤创建的数据表数据
2.3 数据分析–Hive程序步骤:数据统计
通过本步骤对数据进行统计分析,并把输出写入新的 Hive 表。进入步骤3:数据统计,点击进入编辑界面
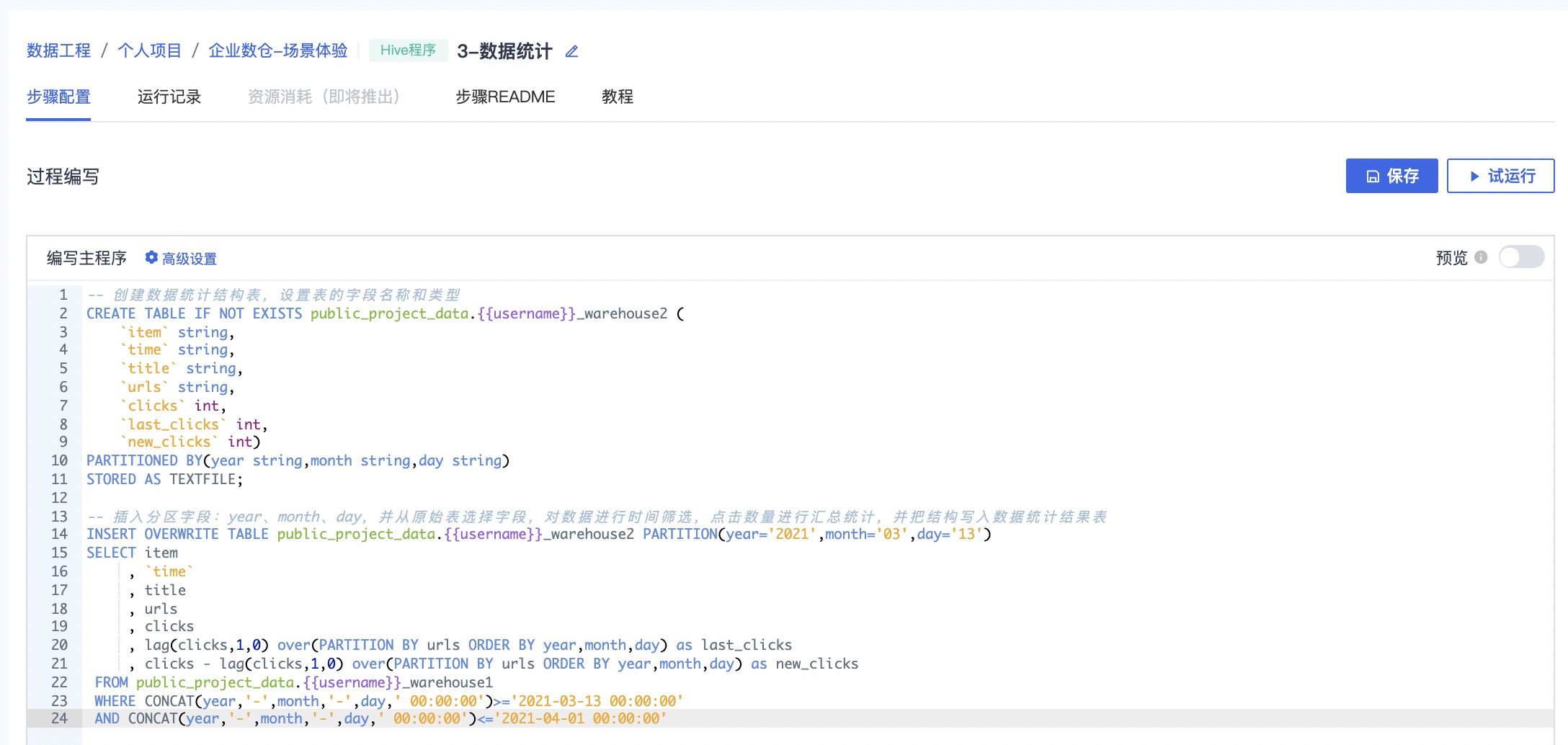
编写主程序
-- 创建数据统计结构表,设置表的字段名称和类型
CREATE TABLE IF NOT EXISTS public_project_data.{{username}}_warehouse2 (
`item` string,
`time` string,
`title` string,
`urls` string,
`clicks` int,
`last_clicks` int,
`new_clicks` int)
PARTITIONED BY(year string,month string,day string)
STORED AS TEXTFILE;
-- 插入分区字段:year、month、day,并从原始表选择字段,对数据进行时间筛选,点击数量进行汇总统计,并把结构写入数据统计结果表
INSERT OVERWRITE TABLE public_project_data.{{username}}_warehouse2 PARTITION(year='2021',month='03',day='13')
SELECT item
, `time`
, title
, urls
, clicks
, lag(clicks,1,0) over(PARTITION BY urls ORDER BY year,month,day) as last_clicks
, clicks - lag(clicks,1,0) over(PARTITION BY urls ORDER BY year,month,day) as new_clicks
FROM public_project_data.{{username}}_warehouse1
WHERE CONCAT(year,'-',month,'-',day,' 00:00:00')>='2021-03-13 00:00:00'
AND CONCAT(year,'-',month,'-',day,' 00:00:00')<='2021-04-01 00:00:00'
保持默认,点击保存后,点击试运行
查看运行记录
运行完成后,可以在运行记录中确认运行结果。
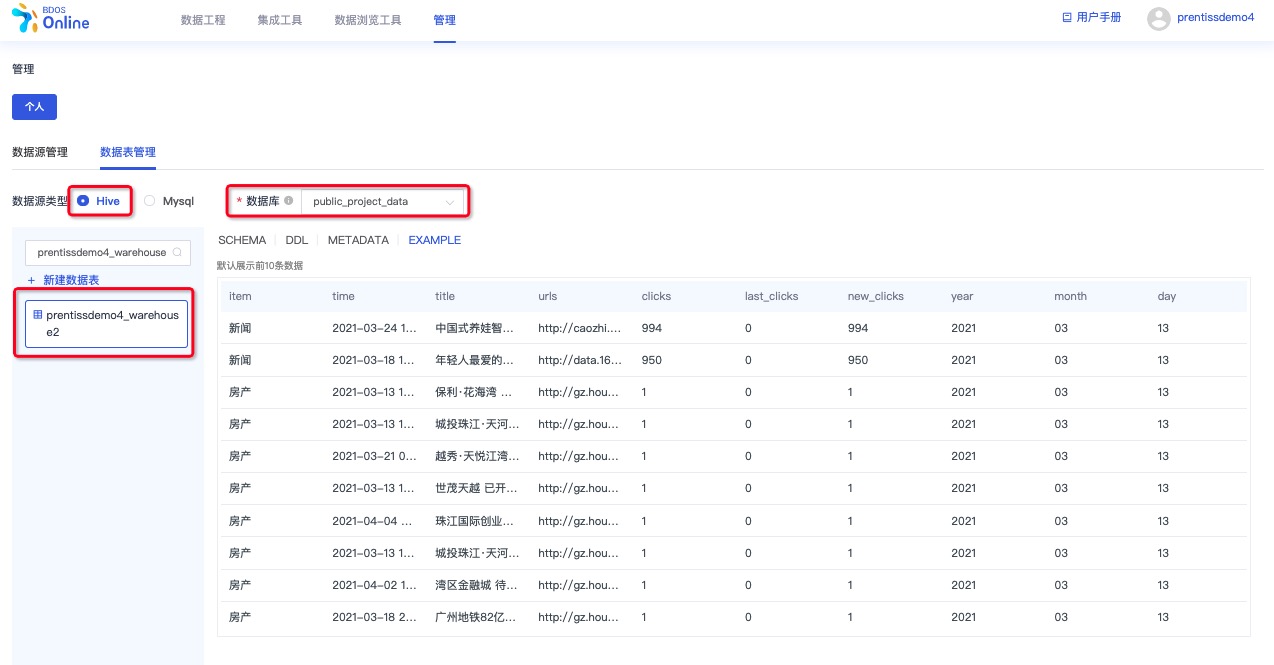
预览数据表
用户从【管理-个人-数据表管理】菜单进入,通过数据源类型和数据库筛选,可预览上一个步骤创建的数据表数据
2.4 数据转换–ETL程序:数据转换导出
通过本步骤,对结果数据进行转换,从 Hive 库转换到目标 MySQL 库。
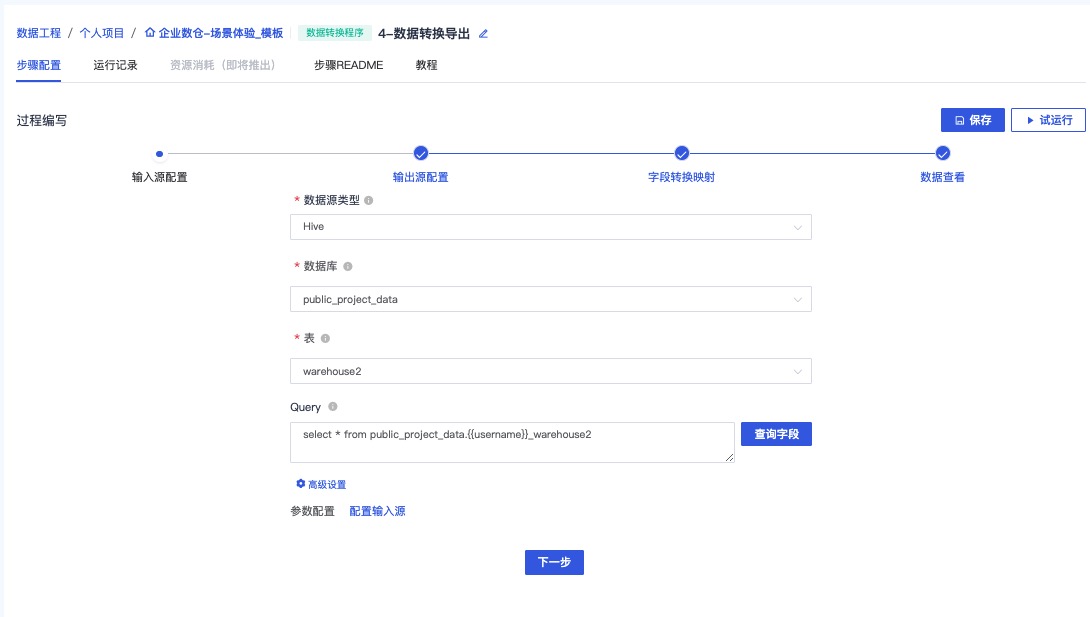
保持默认并点击下一步
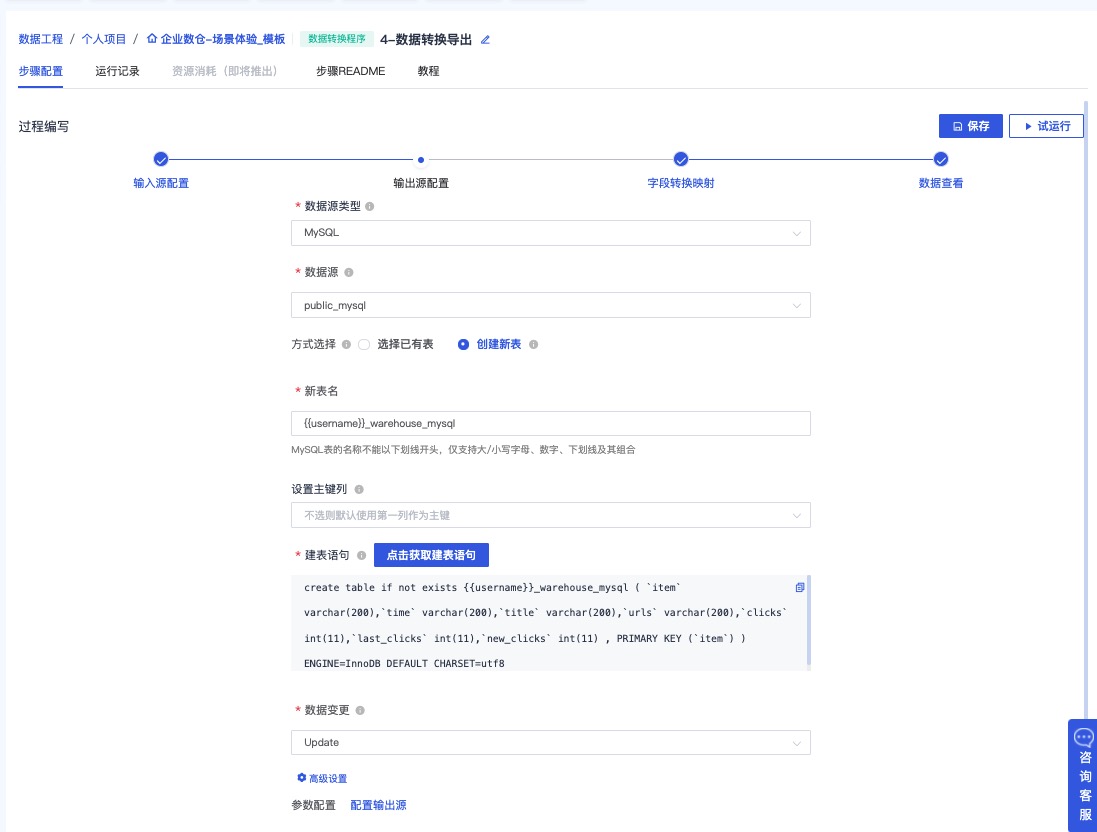
注:请点击获取建表语句
保持默认,并点击下一步
查看字段映射
选择需要检查的字段并进行匹配校验
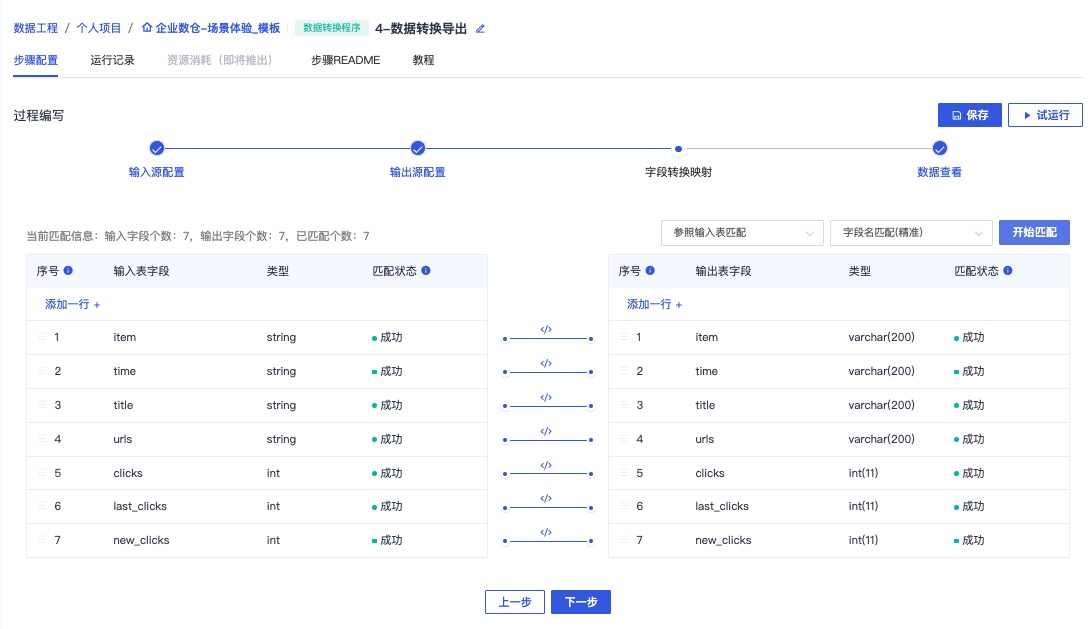
点击下一步
查看样例数据
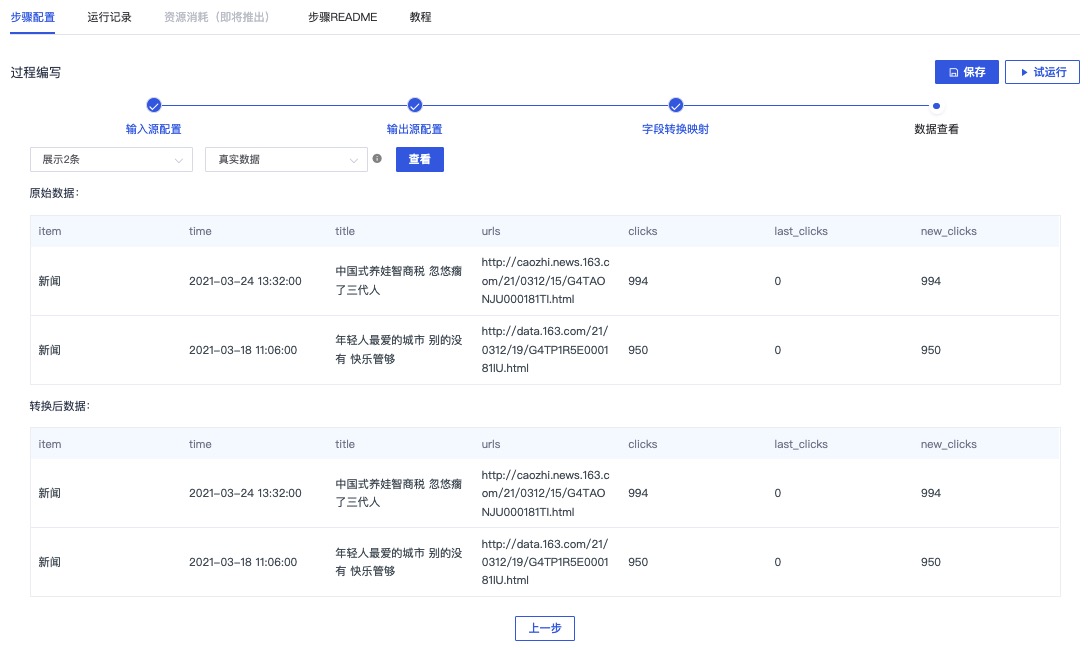
点击保存后,点击试运行
查看运行结果
可点击运行名称进入,查看运行详情
2.5 工作流调度
调整完成后,在项目的工作流与依赖试图界面,将左侧的项目步骤中,逐个拖入试图中,并建立如下图所示的依赖。
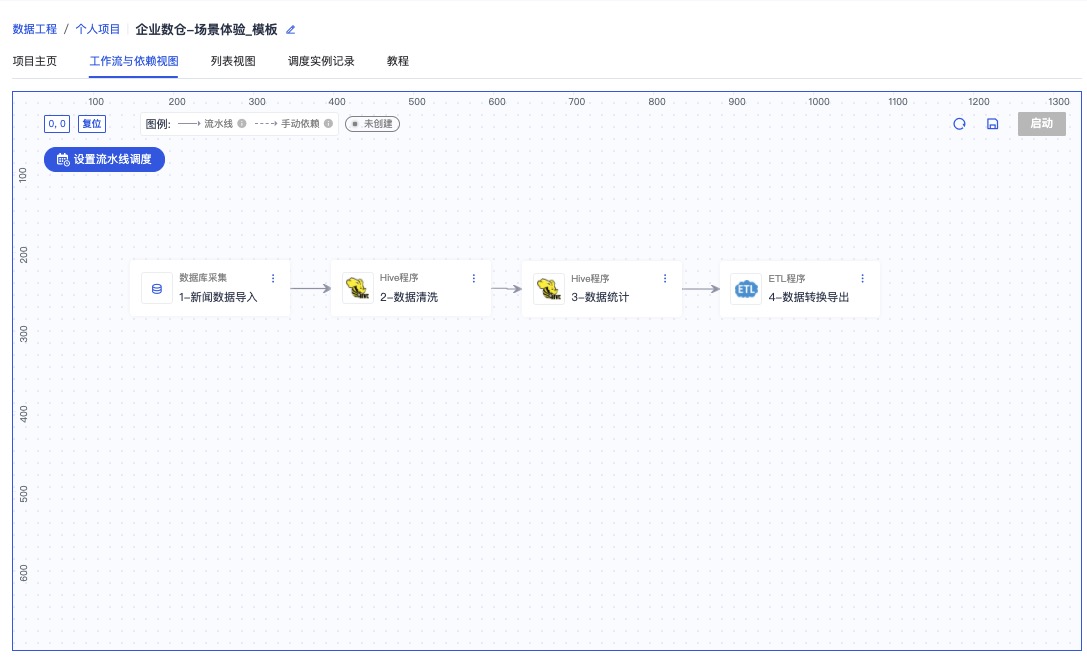
设置调度时间
点击设置流水线调度
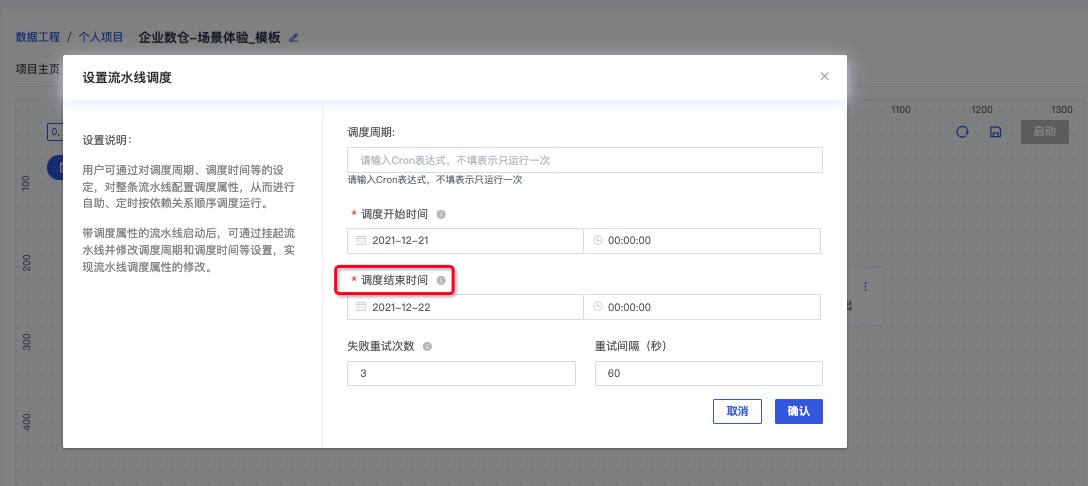
点击确认后点击保存,再启动流水线
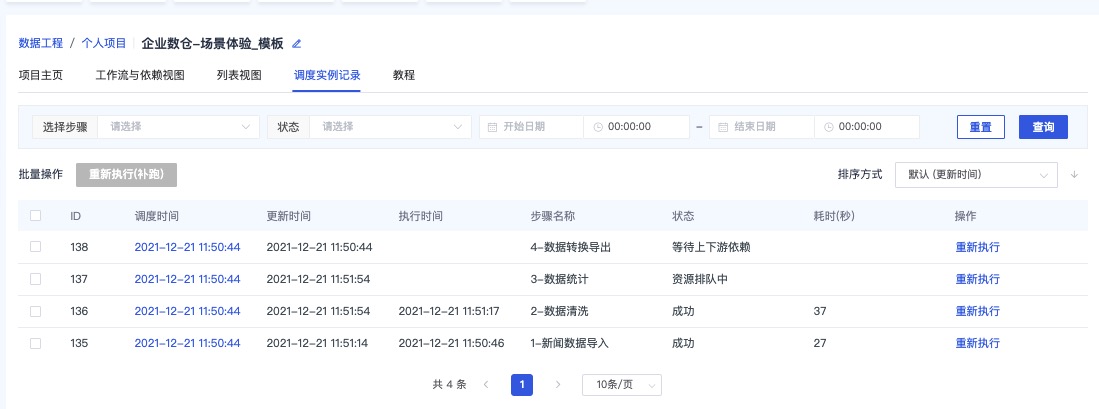
查看流水线运行状态
3. 可视化展示(仅限企业账号)
备注:如需申请企业账号,请联系
用户通过导航【集成工具-机构工具进入】,点击Superset的进入工具图标,跳转至Superset主界面
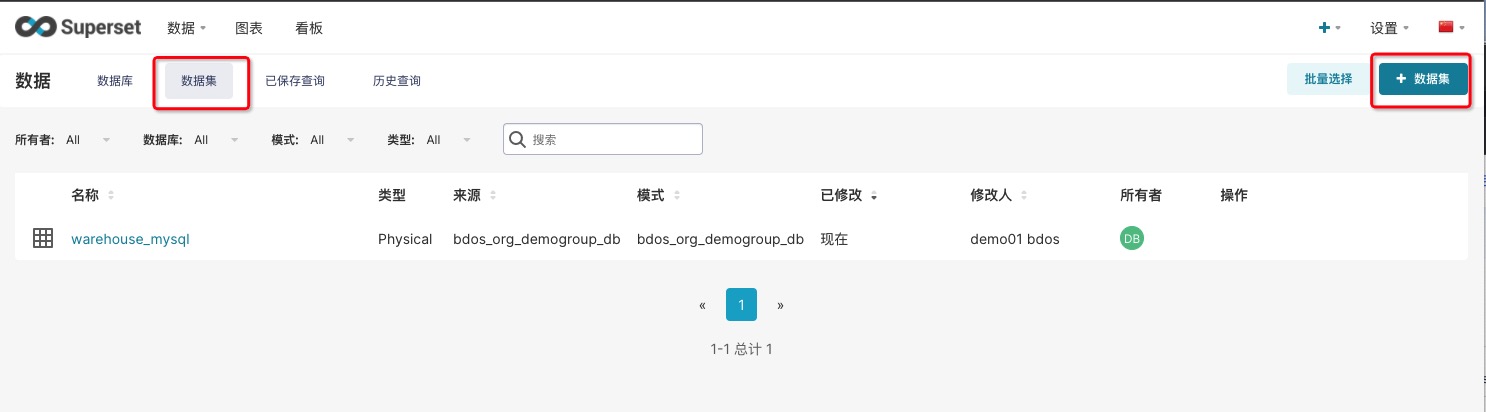
通过Superset导航【数据-数据集】进入,点击+数据集
3.1 添加数据集
| 名称 | 内容 | 描述 |
|---|---|---|
| 数据源 | public_project_data | 选择系统默认提供的MySQL公共数据源 |
| 模式 | public_project_data | 选择系统默认的Schema模式 |
| 表 | 下拉框选择 | 选择需要进行可视化展示的目标表 |

点击新增
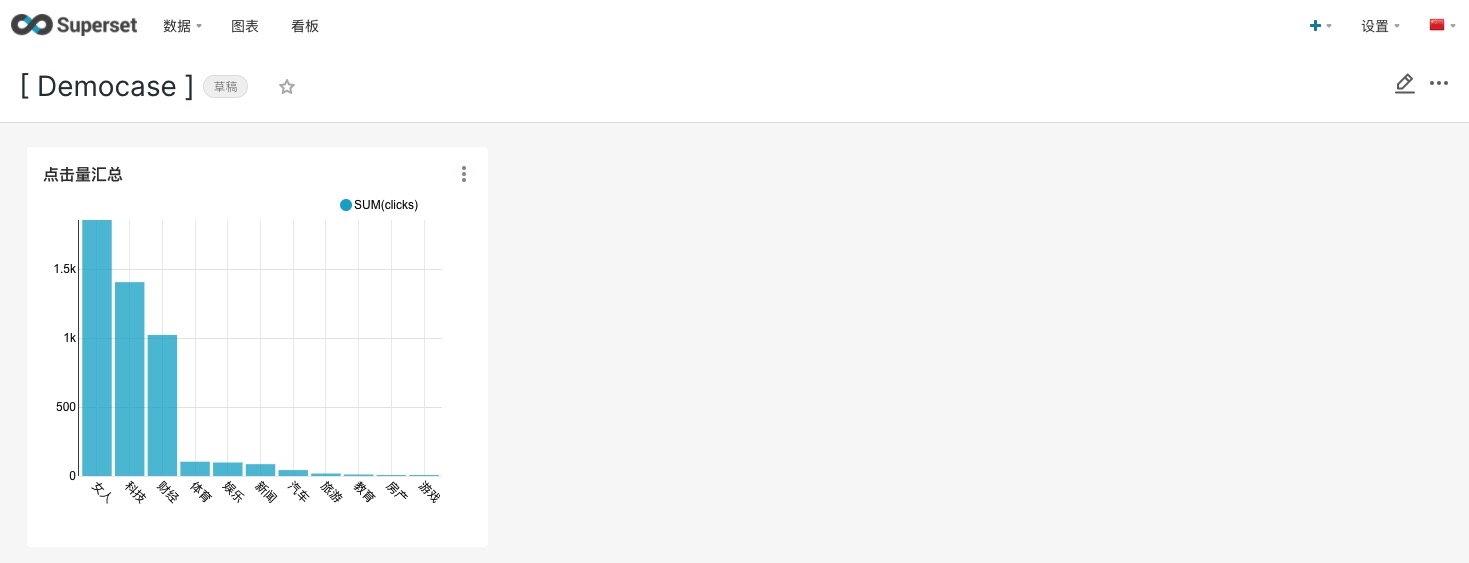
3.2 添加图表
通过菜单导航至【图表】界面,点击+图表

| 名称 | 内容 | 描述 |
|---|---|---|
| 选择数据源 | 下拉框选择 | 选择添加的目标数据集 |
| 表 | 点击选择图表类型 | 选择需要进行展示的图表类型 |
点击创建新图表
| 名称 | 内容 | 描述 |
|---|---|---|
| 指标 | count(*) | 保持默认 |
| 序列 | item | 选择字段作为展示维度,可多选 |
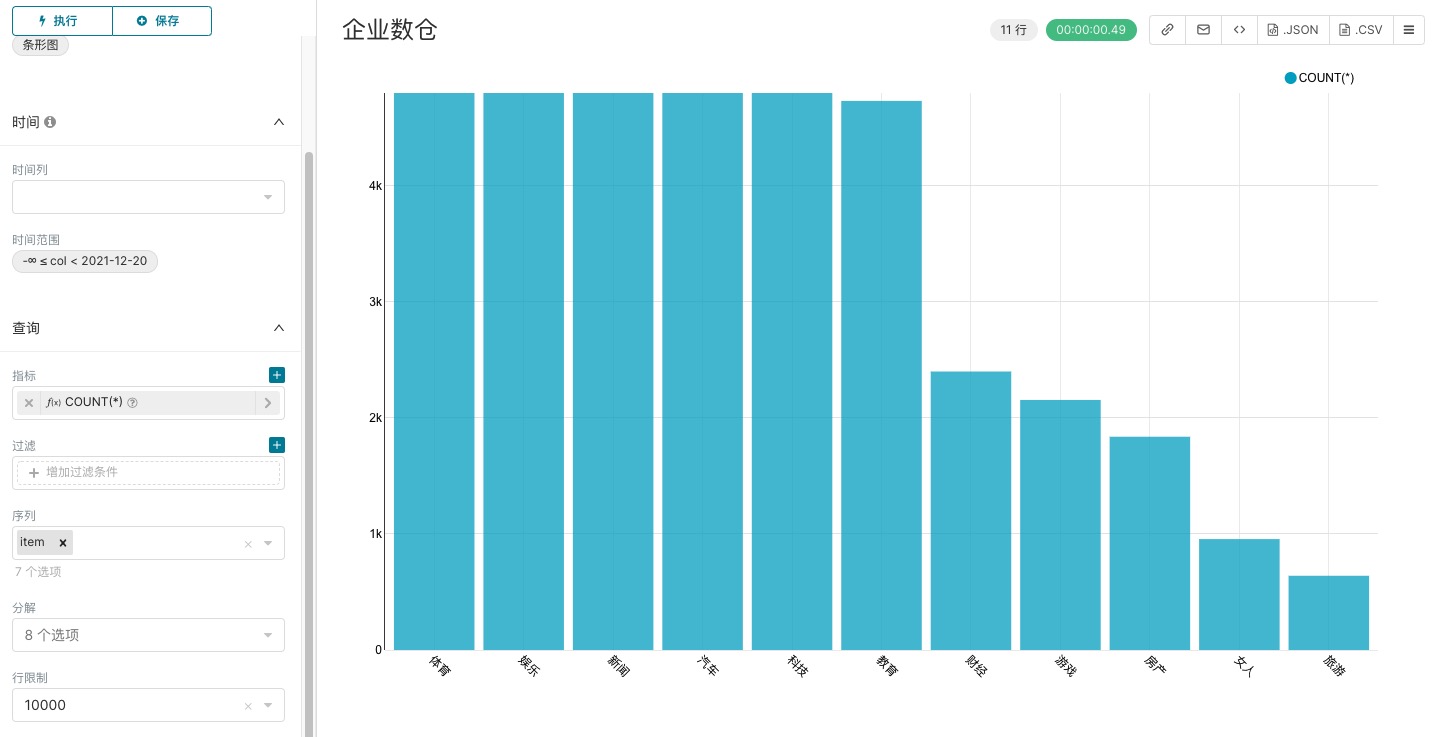
点击执行后,点击保存
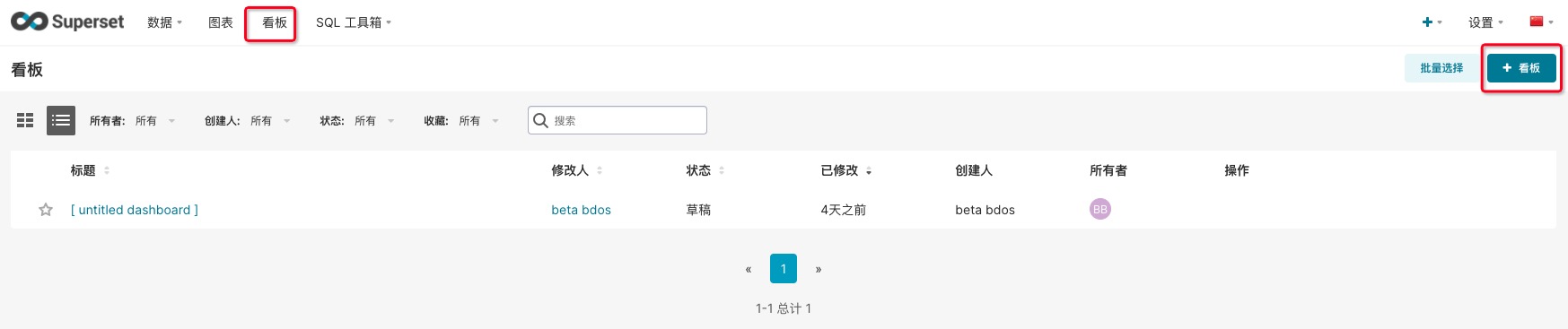
3.3 添加看板
通过菜单导航至【看板】界面,点击+看板
点击编辑图标进入看板编辑界面,选择【图表】,把模板图表手动拖拽添加至左侧看板画布
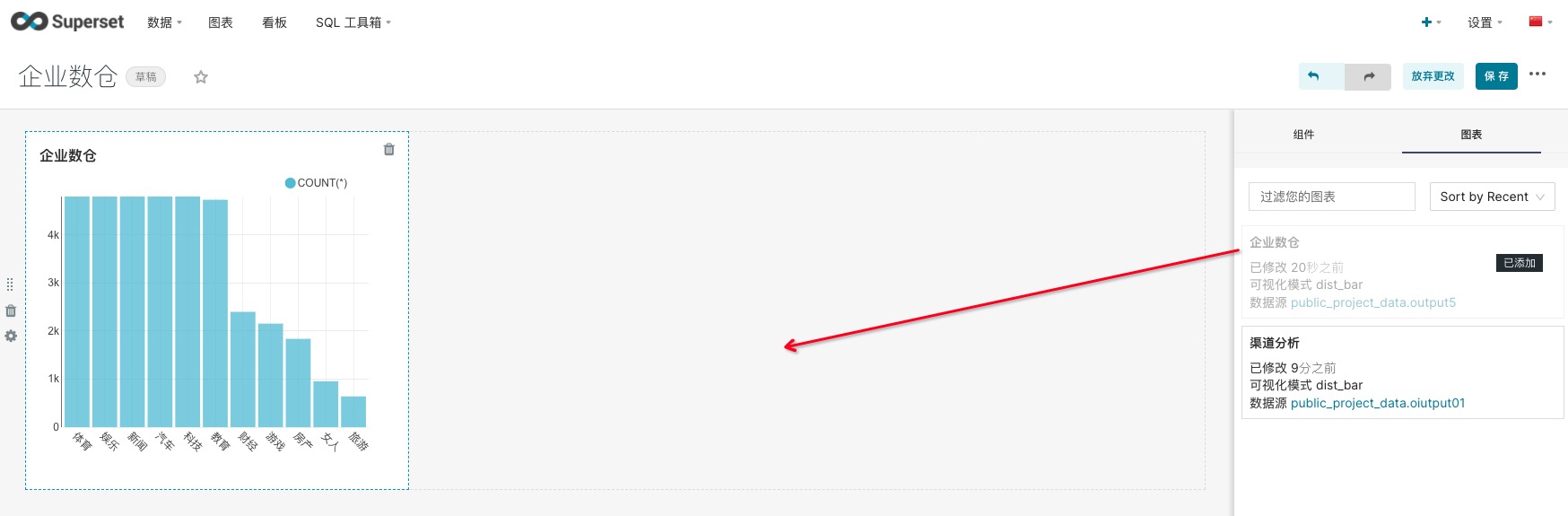
点击保存
欢迎访问网站,注册体验BDOS Online,网站地址:https://bo.linktimecloud.com/

留言
评论
${{item['author_name']}} 回复 ${{idToContentMap[item.parent] !== undefined ? idToContentMap[item.parent]['author_name'] : ''}}说 · ${{item.date.slice(0, 10)}} 回复
暂时还没有一条评论.