BDOS平台上部署Kafka数据流水线
摘要
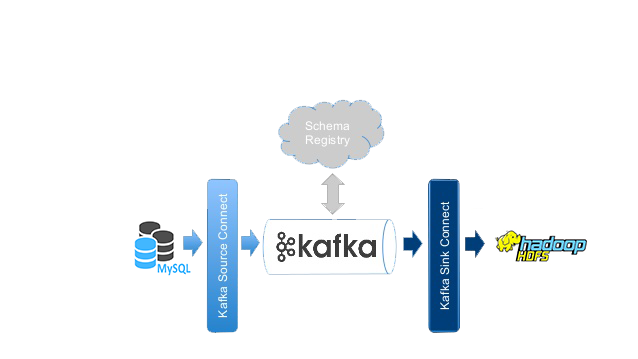
Apache Kafka是一个快速、可扩展的、高吞吐、可容错的分布式发布-订阅消息系统。Kafka具有高吞吐量、内置分区、支持数据副本和容错的特性,适合在离线/实时消息处理、行为跟踪、日志收集、流处理等场景中使用。
Kafka-Connect是一种用于在Kafka和其他系统之间可扩展的、可靠的流式传输数据的工具。它使得快速定义将大量数据集合移入和移出Kafka的连接器(Connector)变得简单。
Connector可以分为Source和Sink两种类型。
- Source类型: 可以把整个数据库或从应用程序服务器收集消息数据送到Kafka Topic,使数据可用于低延迟的流处理
- Sink类型: 可以将数据从Kafka Topic传输到二次存储和查询系统,或者传递到批处理系统以进行离线分析
本博客主要举例说明如何在智领云BDOS平台上使用Kafka和Kafka-Connect进行数据流处理。
简介
使用Kafka处理流式数据包含数据写入(Producer)和数据写出(Consumer)两方面。本博客示例在智领云BDOS平台上同时使用两种类型的Connector,把各种应用服务产生于MySQL中的数据用Source Connector写入到Kafka,然后用Sink Connector写出到HDFS中, 同时可以使用HUE应用查看MySQL和HDFS上的数据。
主要步骤如下:
1. 创建Kafka集群
2. 安装Schema-Registry和Hue
3. 创建Kafka Connect集群
4. 在新建的Kafka Connect集群上安装Source Connector和Sink Connector
5. 在HUE应用中查看MySQL和HDFS上的数据
步骤一:创建Kafka Cluster集群
登录进BDOS平台,点击左侧目录[Kafka] -> [Kafka-Cluster]进入Kafka-Cluster集群管理界面,然后点击右上角[添加]按钮进入集群配置页面:
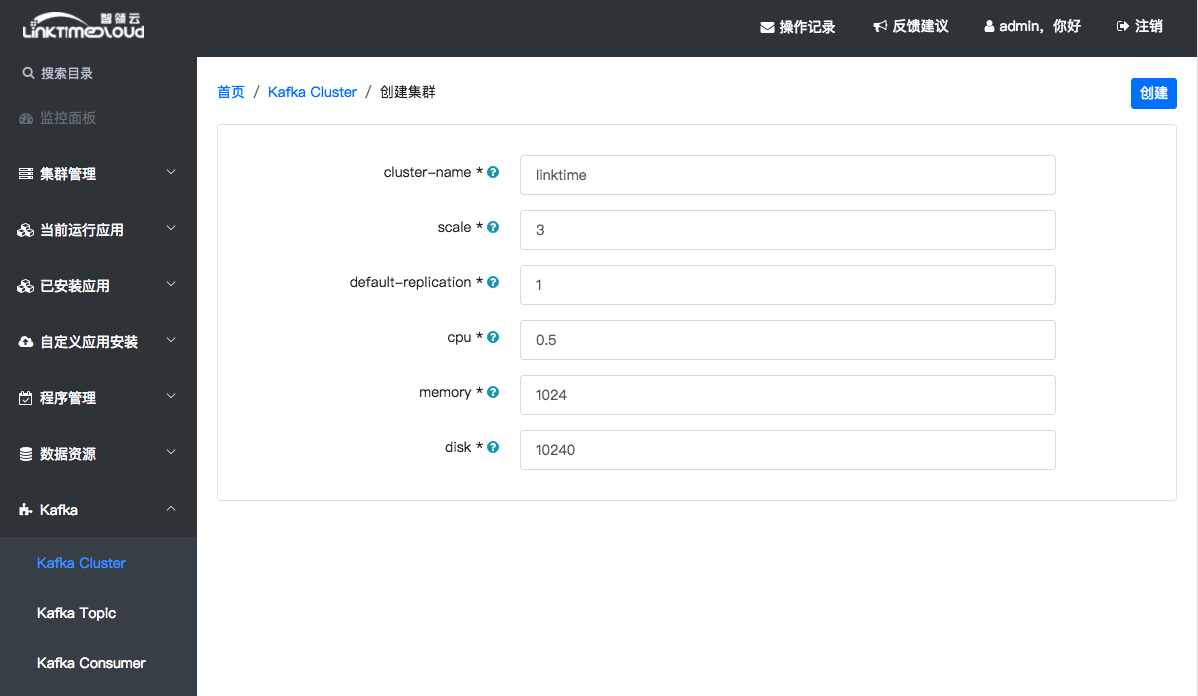
各配置项说明请参考附录1,Kafka Broker数目项scale可以用默认值1(也可选2或3,Broker数目越多集群要分配的资源也会越多,请根据集群的剩余资源来进行配置),其他配置项采用默认值,点击右上角 [创建],然后可以看到Kafka Cluster创建的过程日志,等待直到创建成功返回Kafka-Cluster列表

步骤二:安装Schema-Registry和Hue
Schema-Registry是Data Schema管理服务,在BDOS中,Kafka消息从数据库写入kafka并写入HDFS时采用的是AVRO格式,该格式的数据含有schema信息,用来对数据做序列化/反序列化处理,这时候我们需要使用Schema-Registry来支持该格式的数据;
Hue 是一个开源的智能分析工作台,我们可以在Hue中浏览HDFS上AVRO格式数据,并进行浏览和操作Hive及Mysql中的数据。
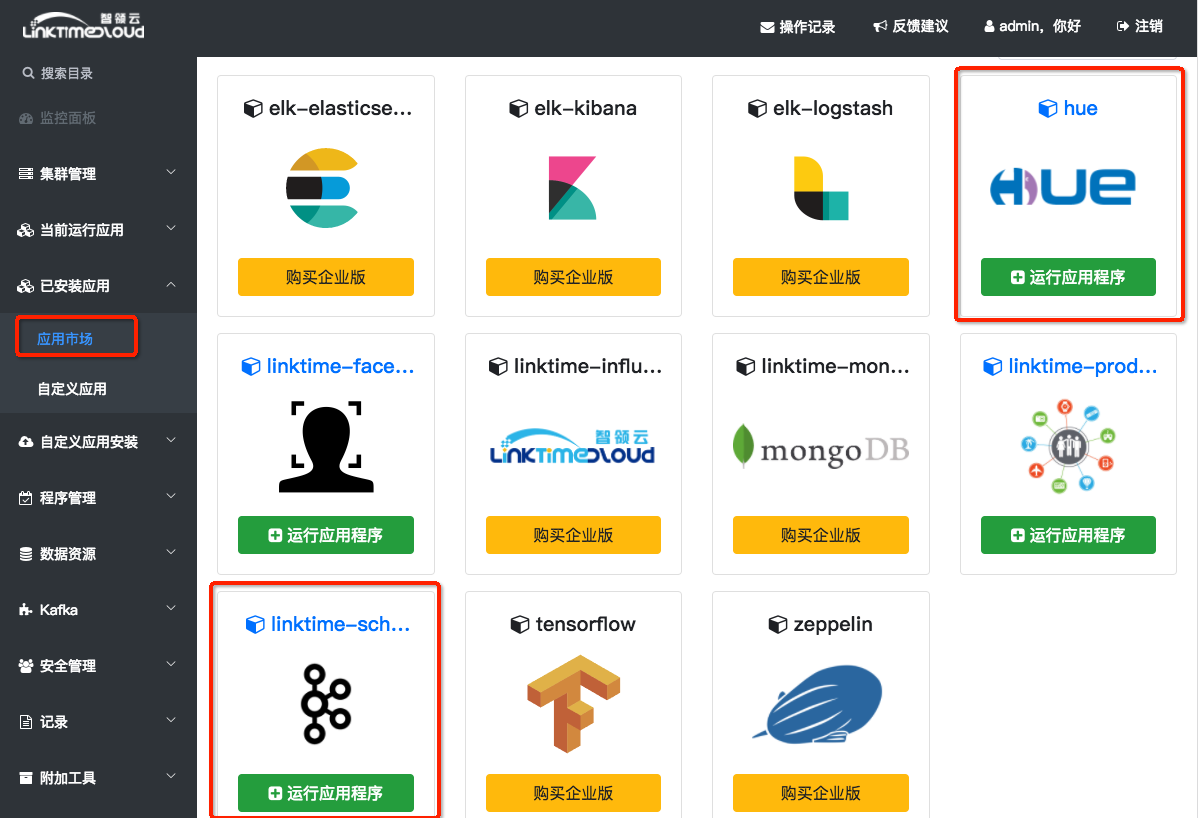
Schema-Registry和Hue的安装步骤是一样的,Schema-Registry的安装步骤如下:
1. 请点击选择左侧目录中的[已安装应用] -> [应用市场],找到 Schema-Registry, 点击[运行应用程序]
(如果找不到应用,可能此应用已经运行,可以在[当前运行应用]里面查看)
2. 进入Schema-Registry详情页面, 点击右上角的[运行应用程序],在弹出框点击[下一步], 再点击[安装]
3. 安装过程会持续一到两分钟,请耐心等待,之后会弹出一个操作记录显示当前安装过程日志;
4. 等待安装完成之后,点击左侧目录[当前运行目录] -> [官方应用]就可以看到Schema-Registry已经在当前运行应用列表里了;

如图Schema-Registry的状态变成 running(1/1) 说明已经安装成功。
然后按照上面步骤安装Hue,具体内容可以查看下面的步骤五: 用HUE查看数据
步骤三:创建 Kafka Connect 集群
在左侧目录点击[Kafka] -> [Kafka Connect]
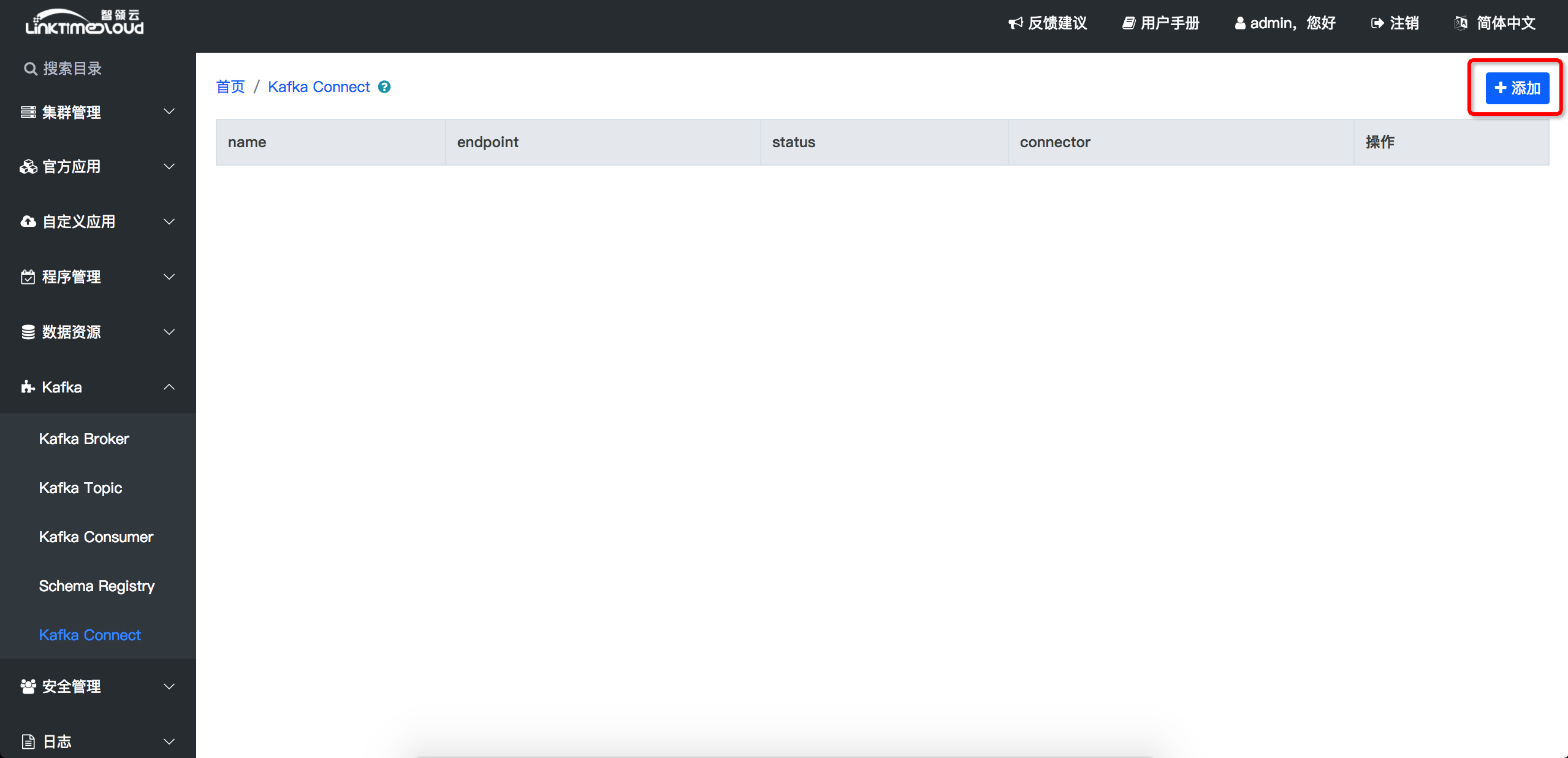
点击右上角[添加],就可以进入集群安装界面了
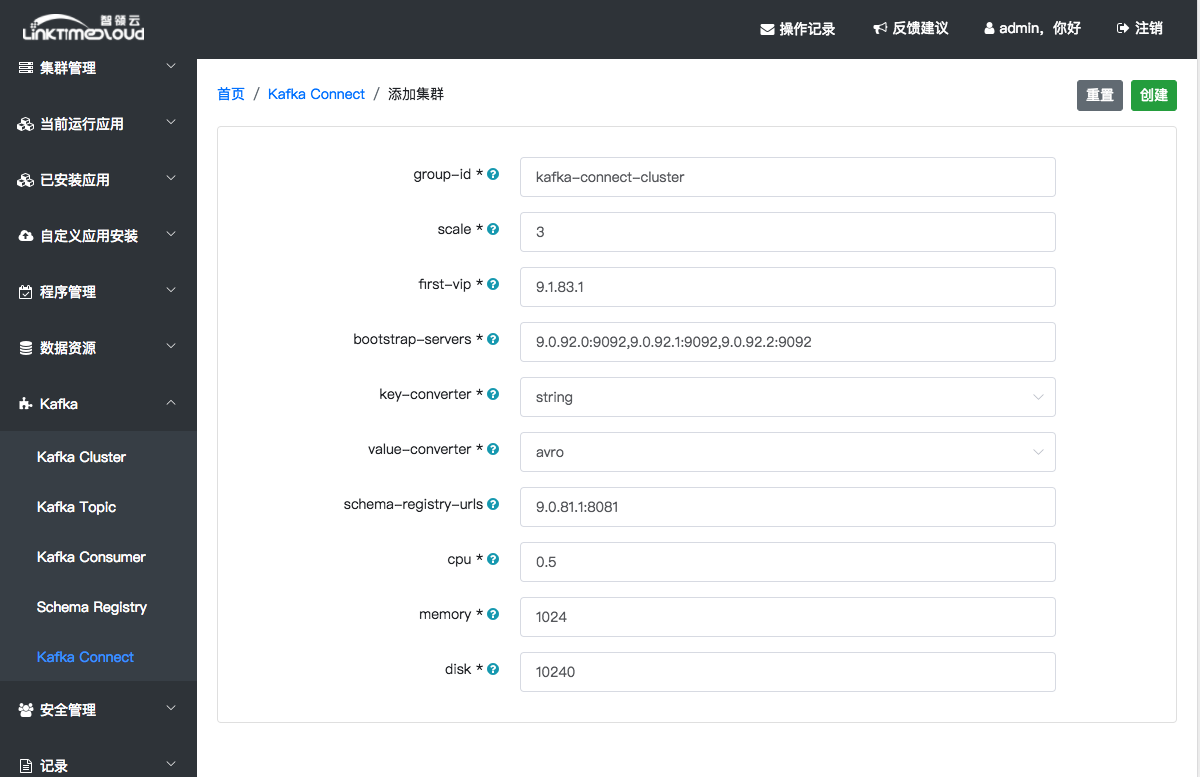
配置项说明:见附录2(所有选项都不支持中文输入):
此处默认Connect集群数目scale是1(增加Connect Server数目会相应地消耗更多的集群资源),所有配置项都可以使用默认值,点击右上角[创建]按钮,等待集群创建。
集群创建之后就返回到集群列表页([kafka] -> [Kafka Connect]);然后在[当前运行应用] -> [系统应用]列表里查看kafka-connect-cluster-X状态(X是一个数字,对应一个Connect Server的编号),如果变成running(1/1)状态说明kafka-connect集群创建成功,可以安装Connector了:

步骤四: 创建Kafka Connector
4.1 安装 JDBCSourceConnector
安装好上面相关服务且Kafka-Connect进入 running(1/1) 之后,接下来我们创建Source类型的Connector,把MySQL中的数据(mysql_faker会模拟生成应用服务数据并写到mysql的mysql_faker数据库里,可以通过HUE查看数据库[mysql_faker]-[product]表里面生成的数据,后面会介绍如何查看)写到Kafka中。
点击左侧目录[Kafka] -> [Kafka-Connect],进入Kafka-Connect集群列表页,点击集群名称kafka-connect-cluster进入Connector列表页面,点击右上角[添加]按钮进去Connector配置页面:
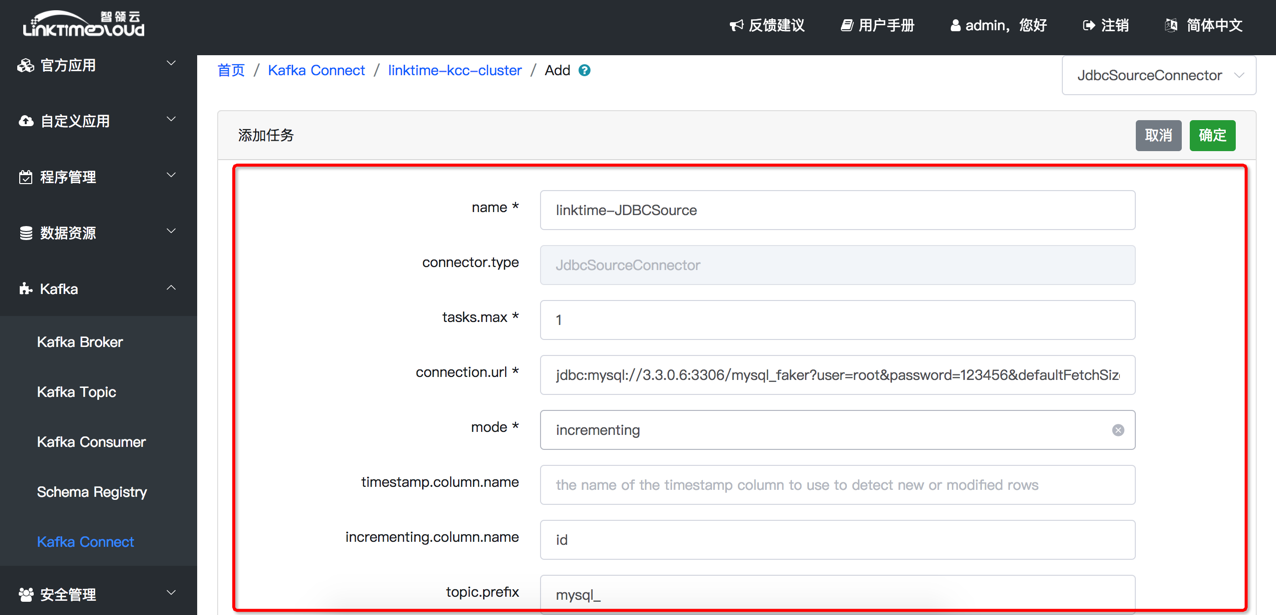
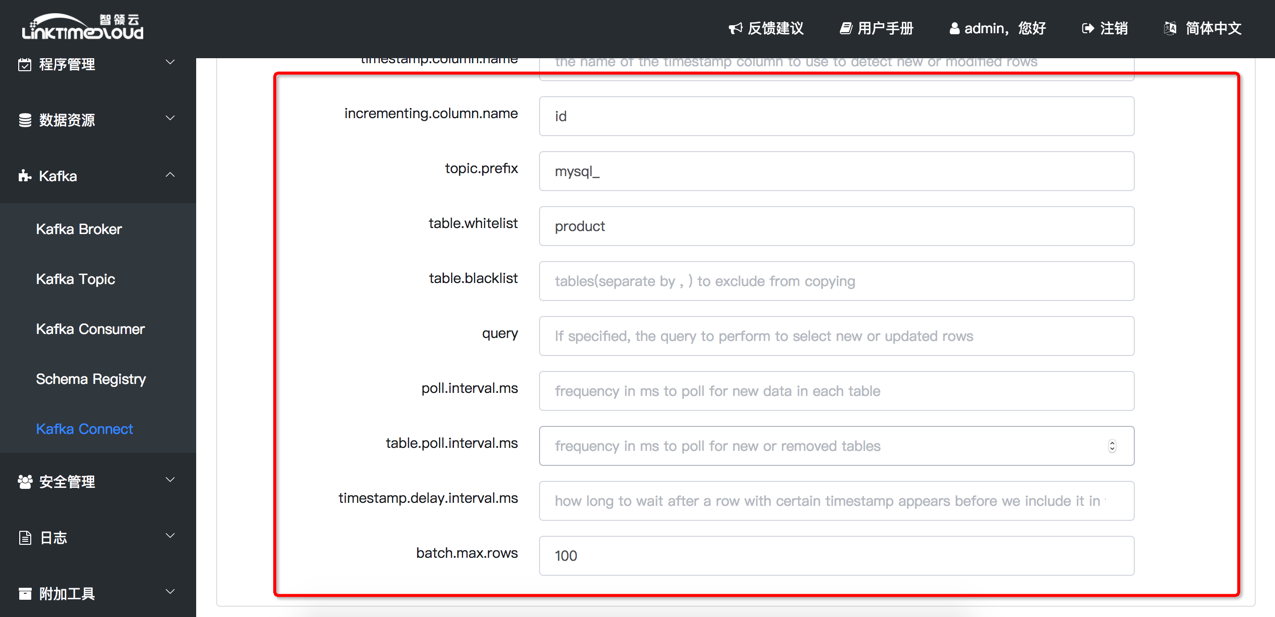
配置选项说明(见附录3):
右上角为Connector 类型,默认选择 JDBCSourceConnector。表格只需填写table.whitelist为 product(存储上面模拟生成数据的数据库表)。表格其他配置项可以采用默认值。
填写好之后点击右上角 [添加] 按钮,就可以添加一个JDBCConnector了,添加完成之后会自动跳转(也可以点击集群列表中的group-id)列出此集群中所有的connector,可能会出现“Cannot get connectors”的错误,刷新即可显示最新创建的connector:
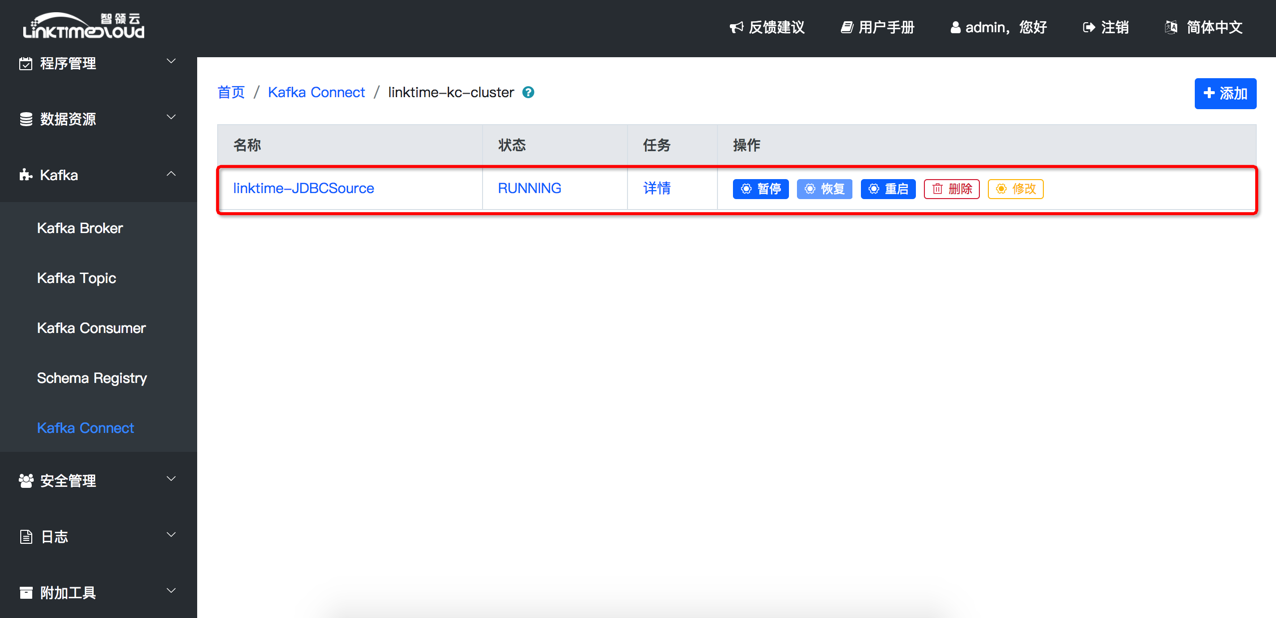
JDBSSourceConnector创建成功之后,大概一分钟左右就可以在Kafka Topic管理界面看到,数据写到了Kafka中 的mysql_product这个topic里面了;点击[Kafka] -> [Kafka Topic],进入Topic列表页,点击[mysql_product]即可进入此Topic详情页,然后点击[刷新]按钮就可以查看mysql_product数据了:
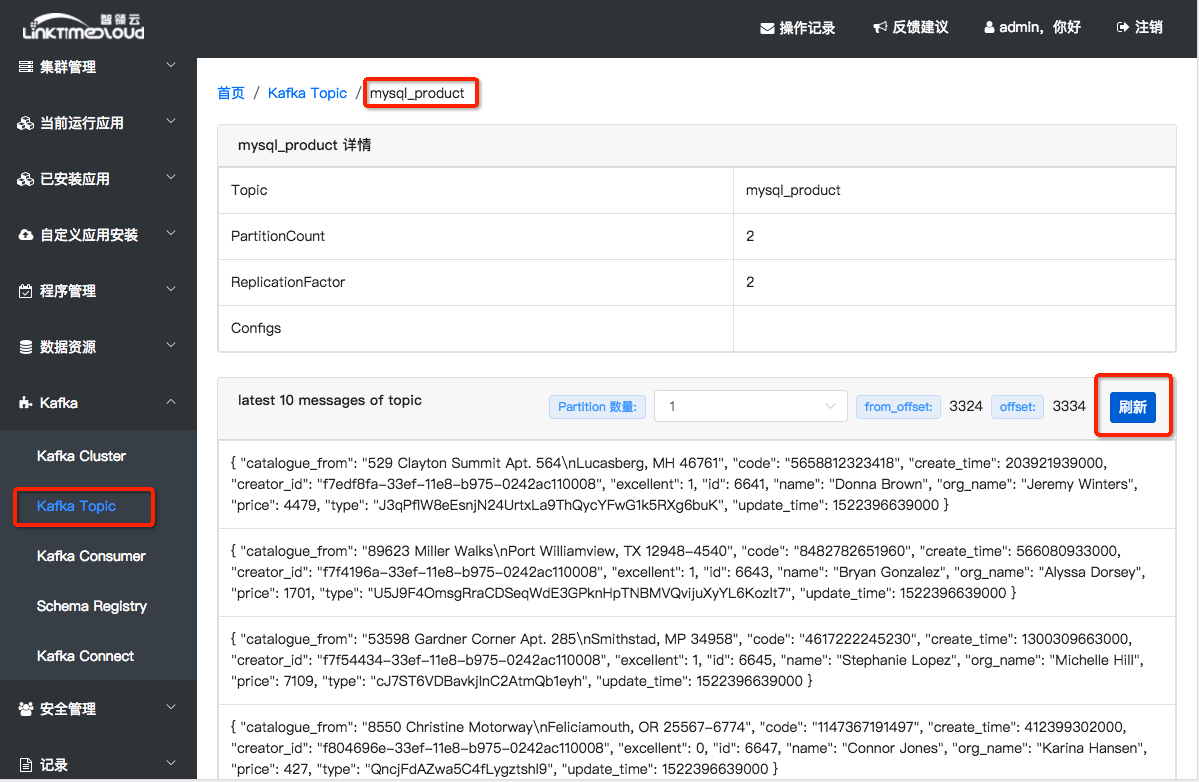
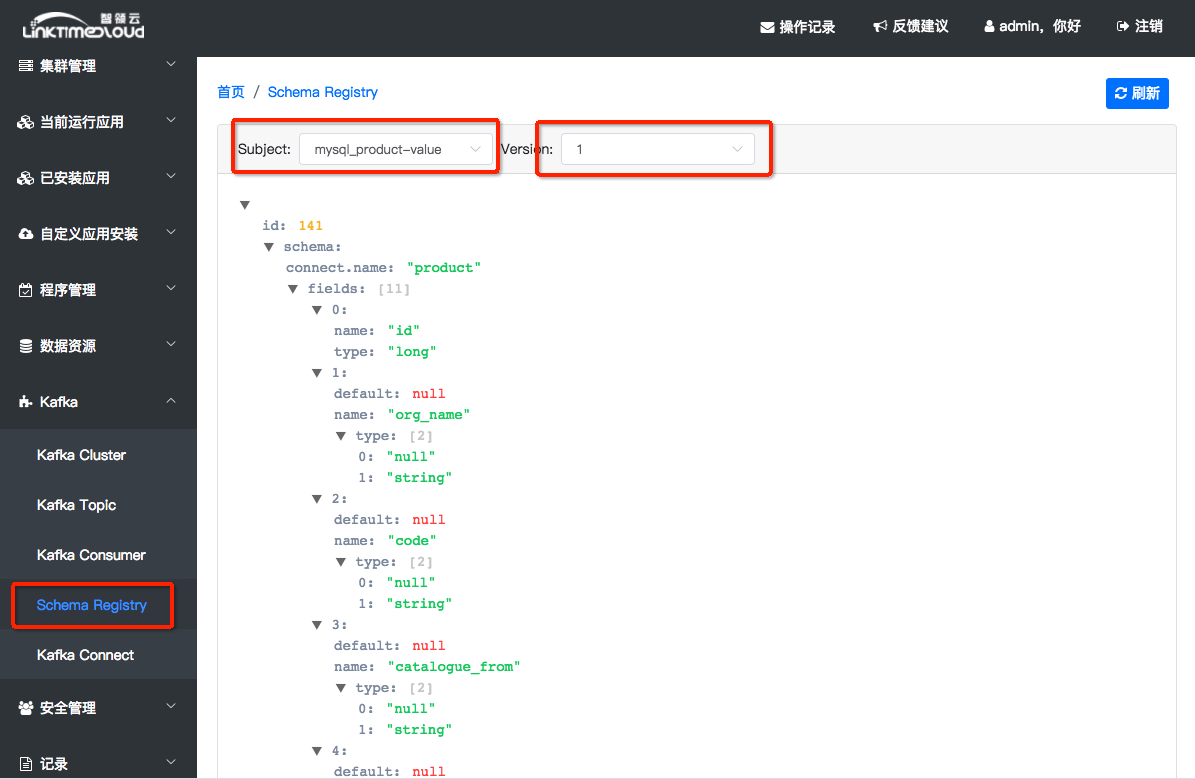
在[Schema Registry]页可以查看mysql_product这个topic数据的schema,点击[Schema Registry],然后选择[mysql_product_value] subjects:
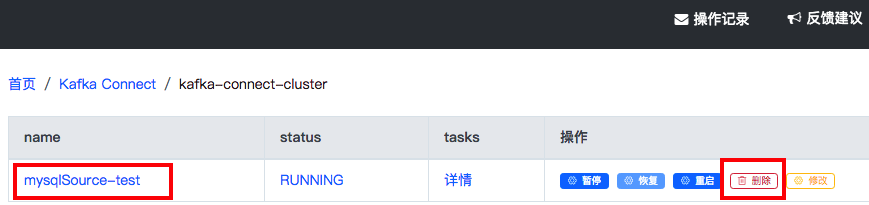
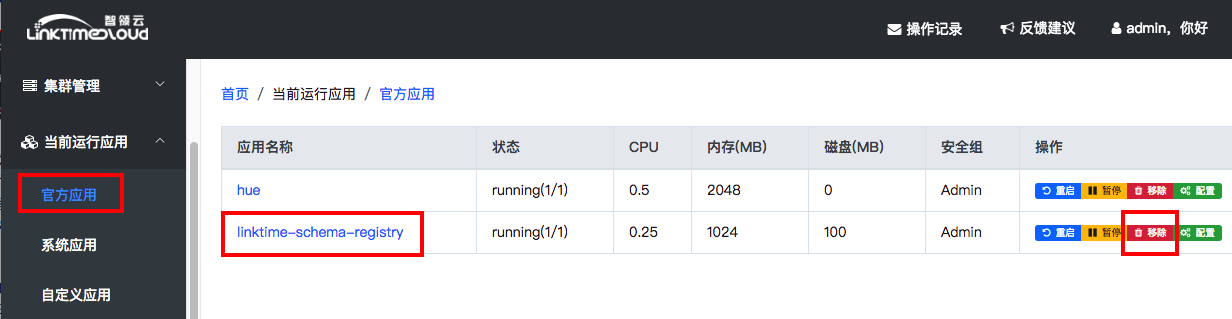
注意,如果JDBSSourceConnector创建后,“status”显示“Failed”并且“tasks”的“详情”里显示了AVRO格式错误的时候,请删除这个Connector,并且在[当前运行应用]的[官方应用]中找到linktime-schema-registry,点击“移除”卸载这个应用,然后重新在应用市场中安装linktime-schema-registry并重新创建JDBSSourceConnector。
4.2 安装 HDFSSinkConnector
添加好JDBCSourceConnector之后,数据就可以从MySQL数据库写到Kafka里;接下来创建HDFSSinkConnector,把数据从Kafka写到HDFS。
同样的,点击[Kafka] -> [Kafka-Connect],进入Kafka-Connect集群列表页,选择刚才创建的Kafka-Connect集群linktime-kc-cluster,点击集群名称linktime-kc-cluster进入Connector列表页面,点击[添加]按钮进去Connector配置页面:
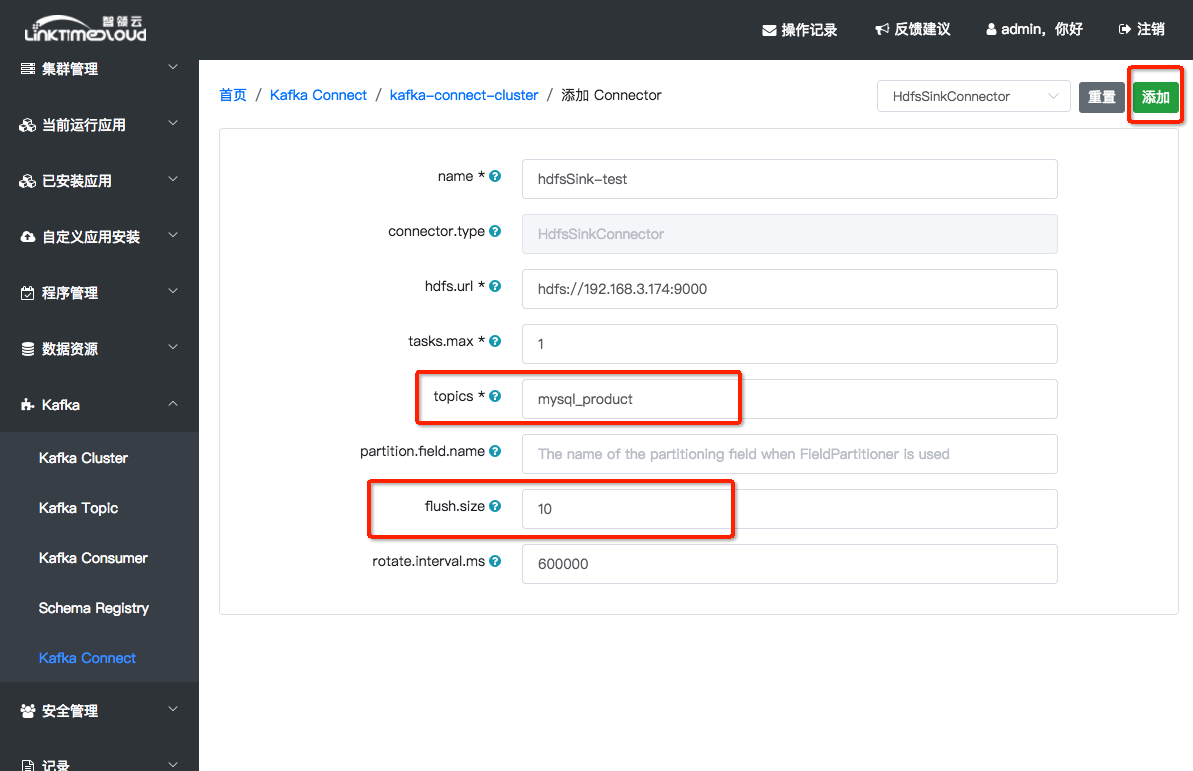
配置选项说明:见附录4
点击右上角的Connector类型选择按钮,选择 HDFSSinkConnector。表格中 topics * 填写 mysql_product,flush.size 填写 10(这个值表示当消息累积到10条的时候HDFSSinkConnector会写入一个AVRO文件到HDFS中,所以这个值越大,HDFS中的文件数目会越少,生产环境下推荐采用10K甚至100K为flush.size)。表格中其他配置项可以直接采用默认值。
填写好之后点击右上角[确定]按钮,等待Connector创建成功,返回到Connector列表页面;
步骤五: 用HUE查看数据
创建好上面两个Connector之后就可以查看数据从Mysql到Kafka,再到HDFS里了,下面介绍如何使用Hue查看Mysql和HDFS里相关的数据:
1、在左侧目录选择[当前运行应用] -> [官方应用] 点击 [hue], 进入hue详情页面,点击[首页],就会跳转到HUE应用首页:

如果是首次进入需要创建用户,用户名:dcos,密码:******,点击创建,创建成功后用该用户名密码登陆;
2、查看MySQL数据
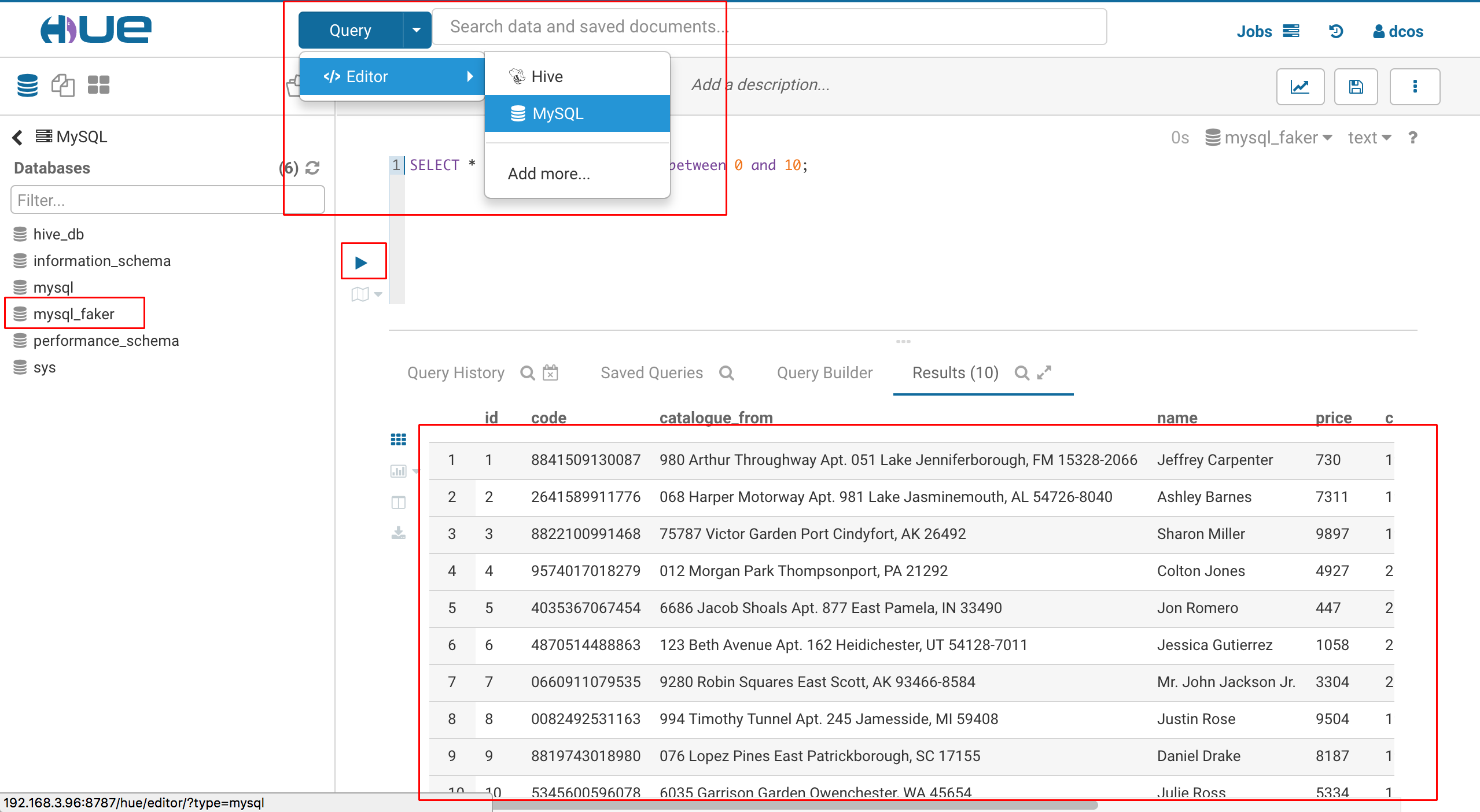
进入HUE后,点击上方的 [Query] -> [Editor] -> [MySQL],然后在左边的 Databases 下选择mysql_faker;然后在中间的编辑器里输入查询语句:
select * from product where id between 0 and 10;
然后点击编辑器左边的小三角就可以查看MySQL里面的数据了,你可以修改上面语句中的起始和终止的数值来查询其他的数据:
3、查看kafka写到HDFS上数据
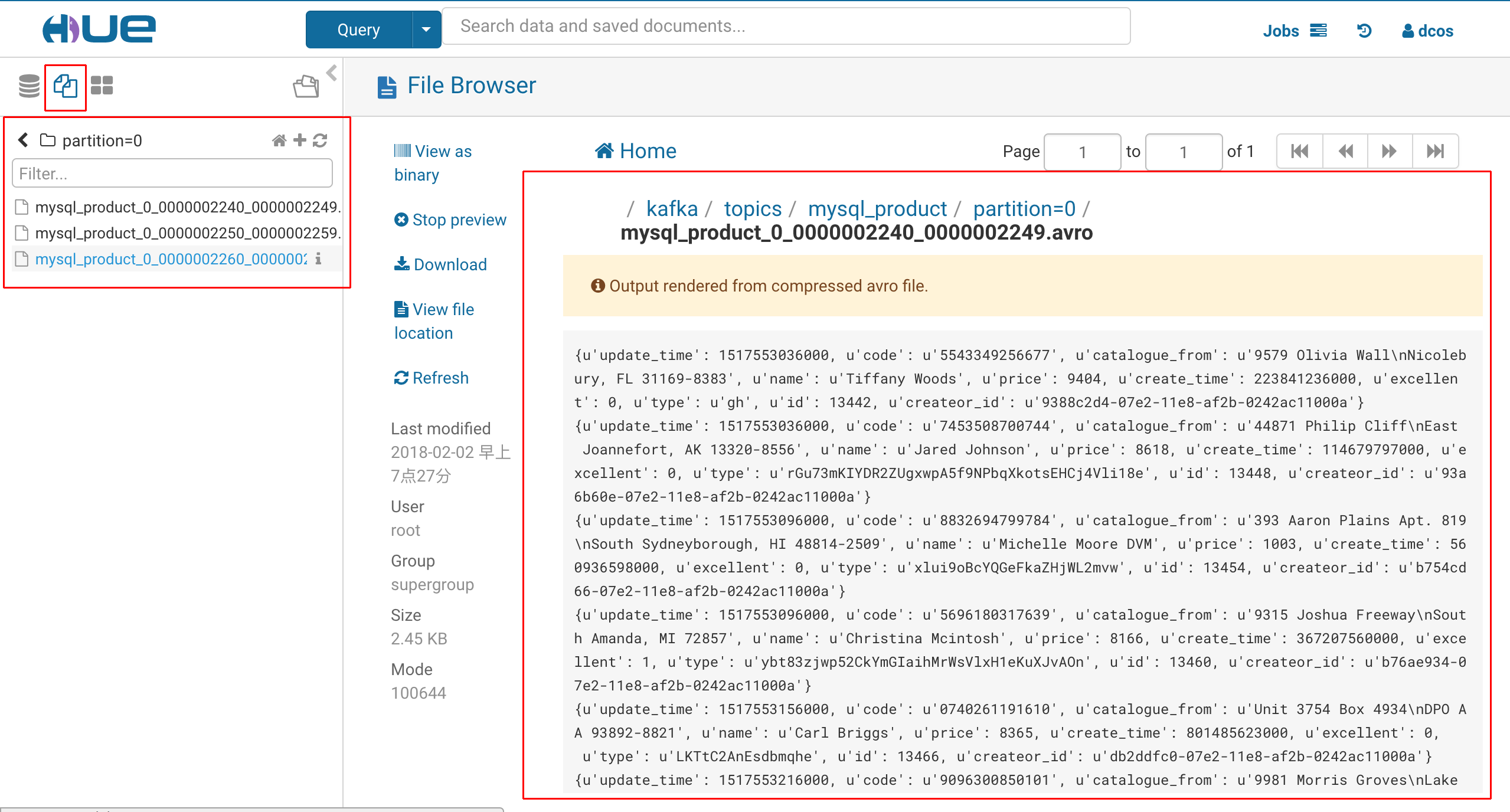


点击左上角的HDFS图标,如果当前目录显示是“dcos”,则点击目录名左边的箭头“10),在Hue里浏览AVRO文件会很慢,有时候会time out报错。生产环境下,我们一般会用Hive查询AVRO数据,而不会直接浏览大数据文件。用Hive查询AVRO格式数据请参看利用Hue玩转Hive这篇博客。
附录
附录1:Kafka Cluster 配置项说明
| 配置项 | 说明 |
|---|---|
| cluster-name | 唯一的集群名称 |
| scale | 集群的规模—Broker的个数 |
| default-replication | Topic的默认副本数,也可以创建Topic时设置,不能大于scale |
| cpu | 单个Broker容器分配的物理机CPU核数 |
| memory | 单个Broker容器分配的物理机内存大小 |
| disk | 单个Broker容器分配的物理机硬盘大小 |
附录2:Kafka Connect 配置项说明
| 配置项 | 说明 |
|---|---|
| groupId | 唯一的集群名称 |
| scale | 集群的规模—节点的个数 |
| first-vip | 集群中第一个节点的vip(后面节点的vip会在第四位基础上增加,所以要保证前三位唯一) |
| bootstrap-servers | kafka集群节点的IP:PORT(可以在[Kafka]—>[Kafka Cluster]列表,点击broker看kafka的节点信息) |
| key-converter | 指明kafka-connect中传输的数据格式(string,json,avro) |
| value-converter | 指明kafka-connect中传输的数据格式(string,json,avro) |
| schema-registry-urls | schema-registry服务的IP:PORT(只有当上面的converter配置了avro才起作用) |
| cpu | 单个节点容器分配的物理机CPU核数 |
| memory | 单个节点容器分配的物理机内存大小 |
| disk | 单个节点容器分配的物理机硬盘大小 |
附录3:Kafka connect JDBCSource connector 配置项说明
| 配置项 | 说明 |
|---|---|
| name | 唯一的连接器名称 |
| tasks.max | 为这个连接器最多创建task的数目 |
| connection.url | JDBC的连接信息 |
| mode | 连接器从JDBC中获取数据的方式(根据时间戳或者自增长字段) |
| timestamp.column.name | JDBC中相关表的时间戳字段(如果mode选择timestamp或者timestamp+incrementing,此项必填 |
| incrementing.column.name | JDBC中相关表的增长字段(如果mode选incrementing或者timestamp+incrementing,此项必填) |
| table.whitelist | 那些需要传输数据到kafka的表,用逗号分隔各个表 |
| table.blacklist | 那些不需要传输数据到kafka的表,用逗号分隔各个表 |
| topic.prefix | 如果query存在, 则为topic的名称, 如果query不存在, 则为topic的前缀 |
| query | 定制化SQL查询语句, 如何使用的query, 不能设置whitelist和blacklist |
| poll.interval.ms | 循环拉取数据的时间间隔,默认是5000ms |
| table.poll.interval.ms | 更新表列表(增加或删除)的时间间隔,默认是60000ms |
| timestamp.delay.interval.ms | Timestamp Column方式的实现原理是每次拉取的数据都是从上次拉取数据的时间到当前时间之间的;假如此选项设置为100,每次拉取的数据从上次拉取数据时间到当前时间减去100ms之间的;这样可以给完成transactions增加缓冲时间 |
| batch.max.rows | 每次拉取数据的最大行数(可以控制connector中的缓冲区) |
附录4:Kafka connect HDFSSink connector配置项说明
| 配置项 | 说明 |
|---|---|
| name | 唯一的连接器名称 |
| tasks.max | 为这个连接器最多创建task的数目 |
| hdfs.url | HDFS的地址 |
| topics | 需要从Kafka写到HDFS的Topic列表,中间用逗号隔开 |
| partition.field.name | HDFS分区依据的字段 |
| flush.size | 写一次文件需要满足的记录数 |
| rotate.interval.ms | 执行写HDFS文件时间间隔,默认是60000ms(这个和上面的flush.size配合使用) |
附录5:添加topic
进入([kafka] -> [Kafka Topic]);点击添加,可以新增topic

留言
评论
${{item['author_name']}} 回复 ${{idToContentMap[item.parent] !== undefined ? idToContentMap[item.parent]['author_name'] : ''}}说 · ${{item.date.slice(0, 10)}} 回复
暂时还没有一条评论.