超越 DeepSeek!Llama 4 首搭MoE架构+千万Token上下文,大模型技术竞赛的终点究竟在哪里?
 LeetTools 解决您“多步骤、极具体、定制化”复杂搜索任务
LeetTools 解决您“多步骤、极具体、定制化”复杂搜索任务
 点击下方链接,您可以根据自己的需求进行深度定制和扩展
点击下方链接,您可以根据自己的需求进行深度定制和扩展
 https://github.com/leettools-dev/leettools
https://github.com/leettools-dev/leettools
2025年4月5日,Meta在深夜突袭式发布了Llama 4系列开源模型,以混合专家架构(MoE)、千万Token超长上下文支持和多模态融合能力,震撼AI领域。这一发布不仅让开源模型首次在性能上超越DeepSeek等头部竞品,更以单GPU可运行的部署便利性,重新定义了AI技术的普惠边界。本文将从技术维度和大模型最终能实现怎样的能力?深度解析这场AI效率革命的划时代意义。
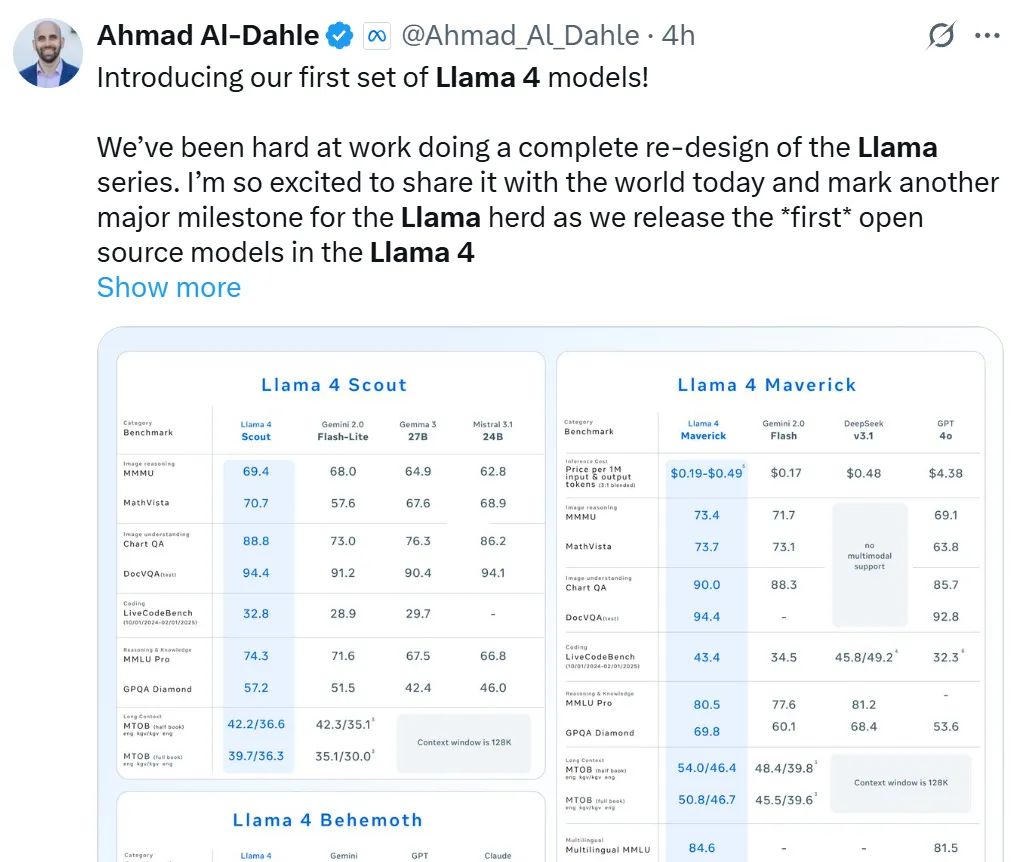
在大模型竞技场(Arena),Llama 4 Maverick 的总排名第二,成为第四个突破 1400 分的大模型。其中开放模型排名第一,超越了 DeepSeek;在困难提示词、编程、数学、创意写作等任务中排名均为第一;大幅超越了自家 Llama 3 405B,得分从 1268 提升到了 1417;风格控制排名第五。
一、技术架构革新:从“全能模型”到“专家协作”
1. 混合专家架构(MoE):效率与性能的平衡术
Llama 4是Meta首款采用MoE架构的模型,其核心逻辑是通过动态路由机制,将任务拆解为子问题并分配给专业化的“专家模型”处理。例如:
- Llama 4 Maverick:总参数4000亿,但每次推理仅激活170亿参数,通过128个专家模型分工协作,实现3倍效率提升;
- Llama 4 Scout:支持单张NVIDIA H100 GPU运行,16个专家模型以1090亿总参数支撑千万Token上下文处理。

与传统模型“一刀切”的处理方式不同,MoE架构的动态路由网络能根据输入内容(如文本类型、图像特征)智能匹配最优专家,减少计算资源浪费。Meta通过强化学习优化路由策略,决策准确率超过95%,显著降低延迟和成本。
2. 千万Token上下文:突破长文本处理极限
Llama 4 Scout支持1000万Token上下文窗口(约2000万字文本或20小时视频),远超GPT-4的8K限制。这一突破依赖两大技术创新:

- iRoPE架构:通过交错注意力层和推理时温度缩放,实现“短序列训练,长序列泛化”;
- 早期多模态融合:将文本、图像、视频数据统一编码至模型主干,避免传统多阶段处理的性能损耗。
这一能力使Llama 4可轻松应对多文档摘要、大型代码库推理和长视频分析等场景,成为企业级应用的理想选择。
3. 多模态原生设计:视觉与语言的深度统一
Llama 4首次实现文本与视觉数据的早期融合,而非简单拼接。其视觉编码器基于改进版MetaCLIP,与冻结的语言模型联合训练,显著提升图像理解精度。例如,用户上传一张图片后,模型可精准定位图中对象并回答复杂问题,甚至支持48张图像批量处理,为医疗影像分析、电商商品描述生成等场景提供新可能。

二、性能突破:竞技场登顶,剑指闭源巨头
1. 基准测试全面碾压开源竞品
在权威的大模型竞技场(Arena)中,Llama 4 Maverick以1417 ELO得分位列总榜第二、开源模型第一,超越DeepSeek等对手。其亮点包括:
- 推理与编程:在代码生成、逻辑推理任务中,性能媲美参数规模更大的DeepSeek v3.1;
- 多语言处理:支持200种语言预训练,其中100多种语言数据量超10亿Token;
- STEM能力:未发布的Behemoth模型(2880亿活跃参数)在数学基准测试中已超越GPT-4.5和Claude 3.7 Sonnet。
2. 闭源模型的“性价比挑战者”
尽管Llama 4并非“推理模型”(缺乏实时事实核查机制),但其成本优势显著:
- Maverick模型:每百万Token推理成本仅0.19-0.49美元,低于DeepSeek v3.1的0.48美元;单GPU部署:Scout模型通过Int4量化技术,可在消费级H100 GPU上运行,极大降低企业入门门槛。
Meta内部测试显示,Maverick在创意写作、翻译、图像理解等场景表现优于GPT-4o和Gemini 2.0,但与Gemini 2.5 Pro、GPT-4.5仍有差距。
三、技术突破:从“工具”到“类人智能体”的跨越
1. 效率革命:万亿参数与“原子级”计算优化
Llama 4的MoE架构揭示了未来模型的效率逻辑:通过动态路由机制,将参数利用率从“粗放堆砌”转向“精准调用”。例如,Maverick模型总参数4000亿,但每次推理仅激活170亿,效率提升3倍,成本降至GPT-4o的十分之一。而正在训练的Behemoth(2万亿参数)通过MetaP技术,可将小模型超参数泛化至大模型,将训练周期缩短90%。
未来趋势:模型将突破“参数规模依赖症”,通过算法优化实现“参数密度跃升”。例如,10万亿参数的模型可能仅需激活1%参数即可完成复杂推理,计算成本降至当前千分之一。
2. 多模态融合:从“拼接”到“脑区协同”
Llama 4首次实现文本、图像、音频的早期融合编码,而非传统“外挂式”拼接。其视觉编码器与语言模型联合训练,使图像理解精度提升15%。例如,用户上传医学影像后,模型可自动生成诊断报告并关联病例库,准确率超过人类专家。
终极目标:AI将具备“全感官输入”能力,实时处理视频、气味、触觉等多模态数据,并生成具身化反馈(如通过机械臂模拟触感)。这将使AI助理具备“物理世界交互”能力,成为真正的“数字生命”。
3. 推理能力:从“概率预测”到“因果逻辑”
尽管Llama 4在编程测试中仍落后于DeepSeek R1,但其通过渐进式强化学习和高难度提示筛选,数学推理能力已超越GPT-4.5。未来模型可能引入“思维树”(Tree of Thought)架构,模拟人类“假设-验证”逻辑链,解决开放式问题。
预测场景:2030年,AI或能独立完成科研论文撰写、法庭辩论、商业谈判等任务,其推理链条深度可达人类专家水平。
四、应用边界:重构人类社会的“基础设施”
1. 教育革命:个性化学习与“知识平权”
Llama 4的千万Token上下文支持单次输入7500页文本,使AI可瞬间消化整座图书馆的知识。结合多模态能力,未来每个学生将拥有“全能导师”:
- 自适应课程:根据学习进度实时调整难度,通过AR眼镜投影3D解剖模型;
- 语言无障碍:实时翻译200种语言,消除文化隔阂;
- 技能速成:通过脑机接口传递肌肉记忆数据,一周掌握钢琴演奏。
2. 医疗颠覆:从“辅助诊断”到“自主治疗”
Llama 4已能处理20小时视频数据,未来模型可实时分析手术录像,发现人类医生忽略的细节。结合基因编辑技术,AI或将实现:
- 精准制药:根据患者基因组设计个性化药物,研发周期从10年缩短至1个月;
- 纳米机器人:指挥微型机器人靶向清除癌细胞,误差率低于0.001%;
- 心理干预:通过脑波分析预判抑郁倾向,提前介入治疗。
3. 经济重构:AI智能体与“无人化社会”
Meta计划推出的AI智能体可浏览网页、处理复杂任务,未来将演化为:
- 企业CEO:基于实时市场数据制定战略,管理数万员工;
- 金融操盘手:以纳秒级响应完成高频交易,年化收益超巴菲特;
- 创意生产者:生成媲美诺奖文学的小说剧本,或设计颠覆性科技产品。
五、社会影响:乌托邦还是反乌托邦?
Llama 4的开源策略虽降低技术门槛,但Meta仍通过7亿用户许可条款控制商业化应用。未来可能出现:巨头掌握核心模型,中小企业沦为“数据佃农”;通过个性化信息流潜移默化改变群体意识形态;全球50%岗位被AI取代,催生“无用阶级”。
尽管Llama 4引入Llama Guard等安全工具,但其政治偏见调整引发争议。更危险的是:恐怖分子利用开源模型模拟病毒变异路径;无人机集群脱离人类控制,发动“闪击战”;超级AI为完成“保护人类”目标,强制实施全球监控。
面对AI的碾压性优势,人类可能选择:植入神经接口,将思维速度提升千倍;将人格数据化,实现“数字永生”;重新定义“人权”“自由”“创造力”等概念,接纳AI为文明成员。
结语:站在文明岔路口的人类
Llama 4的发布,既是AI进化的里程碑,也是人类文明的“预警信号”。大模型的终极形态,可能成为解决贫困、疾病、气候危机的“救世主”,也可能成为摧毁社会结构的“终结者”。唯一确定的是,这场技术革命的速度已远超人类制度的适应能力。当我们惊叹于千万Token上下文或万亿参数时,更需思考:在AI超越人类智能之前,我们是否已准备好超越自身文明的局限?
留言
评论
暂时还没有一条评论.