T6-机器学习模型训练及应用产品操作指南
T6-机器学习模型训练及应用
适用BDOS版本
本教程适用 BDOS v3.4.0 及其后版本
实验设计
本实验使用BDOS来演示一个全流程的机器学习过程,其中包括
- 实验数据及使用算法介绍
- 环境介绍
- 第一部分: 训练集数据导入
- 第二部分: 基于python的机器学习程序拆解,训练模型
- 第三部分: 发布模型服务
- 第四部分: 使用模型服务
- 第五部分: 补充步骤
- supplement-a: 自定义安装一个Jupyter 应用
- supplement-b: 制作一个用于机器学习调度的自定义作业
实验数据及使用算法介绍
本实验使用的数据集是公共网络提供的一份鸢尾花的数据样本,数据抽样(3条)如下:
| sepal_length | sepal_width | petal_length | petal_width | species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 7 | 3.2 | 4.7 | 1.4 | versicolor |
| 5.8 | 2.7 | 5.1 | 1.9 | virginica |
字段解释:
- sepal_length: 花萼长度
- sepal_width: 花萼宽度
- petal_length: 花瓣长度
- petal_width: 花瓣宽度
- species: 生物种类
- setosa:山鸢尾
- versicolor:杂色鸢尾
- virginica:维吉尼亚鸢尾
本实验使用的机器学习算法为”决策树”,通过对花萼、花瓣的长宽进行训练得到模型,对外提供服务。那么当一个新的花进入的时候,它的长宽数据就会作为输入,随后进行预测出得出新的花所属于的种类。以下是一个图式说明
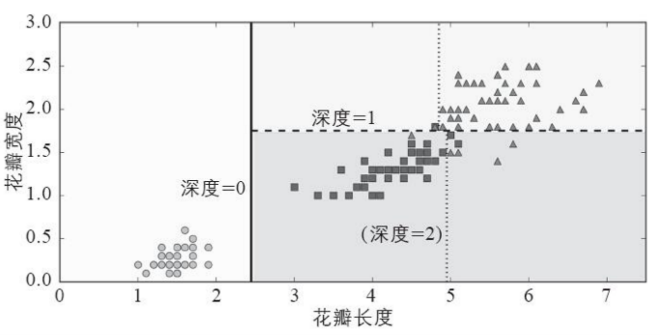
决策树是非常直观的,且很容易解释,这类模型被称为白盒模型。与之相反的,随机森林或是神经网络被认为是一种黑盒模型。它们能做出很棒的预测,但很难解释清楚它们为什么做出这样的预测。
环境介绍
- 本实验的内容适用BDOS v3.4.0 及以上版本
- 本实验进行演示的环境为「智领云对外公共演示平台:Gallery」,实验中展示的具体操作路径和客户侧使用的完全一致,用户在使用中请依照路劲来替换具体的参数和数值
第一部分: 训练集数据导入
为了简化整个流程,本实验使用BDOS集群附带的 Mysql 数据库来作为数据集的存储介质,以下进行数据集导入步骤演示
附:实际生产中, 用户可以使用自己的数据库
第二部分: 基于python的机器学习程序拆解,训练模型
step-1: 获得BDOS Mysql 的地址
登录集群(请核实登录账号在管理员安全组),打开应用管理, 然后打开当前运行应用
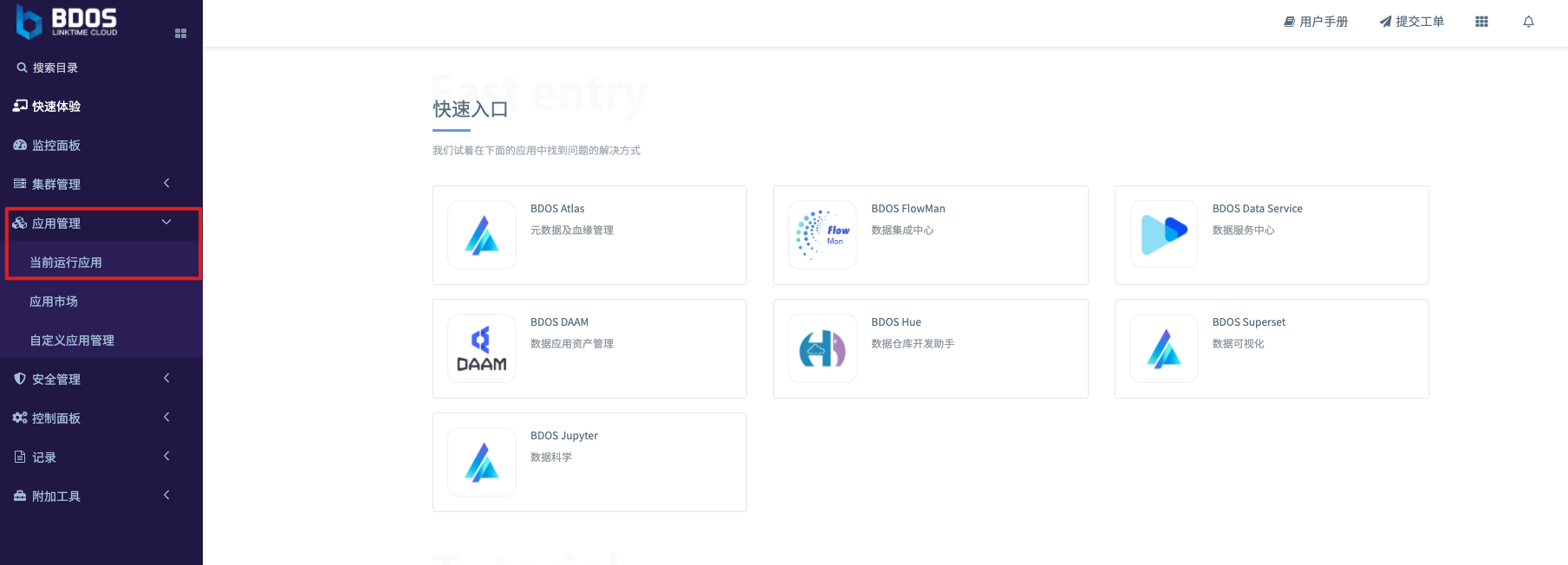
在系统应用中搜索 Mysql, 找到 admin-linktime-mysql,点击打开进入应用页面
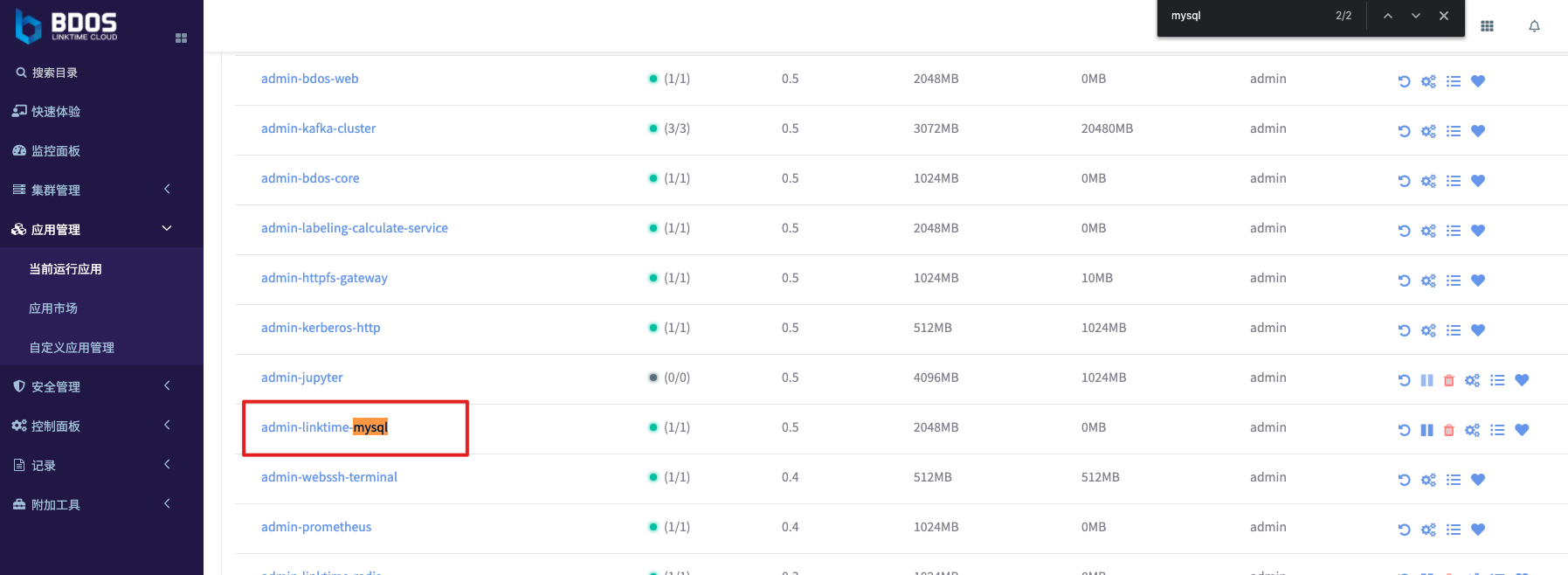
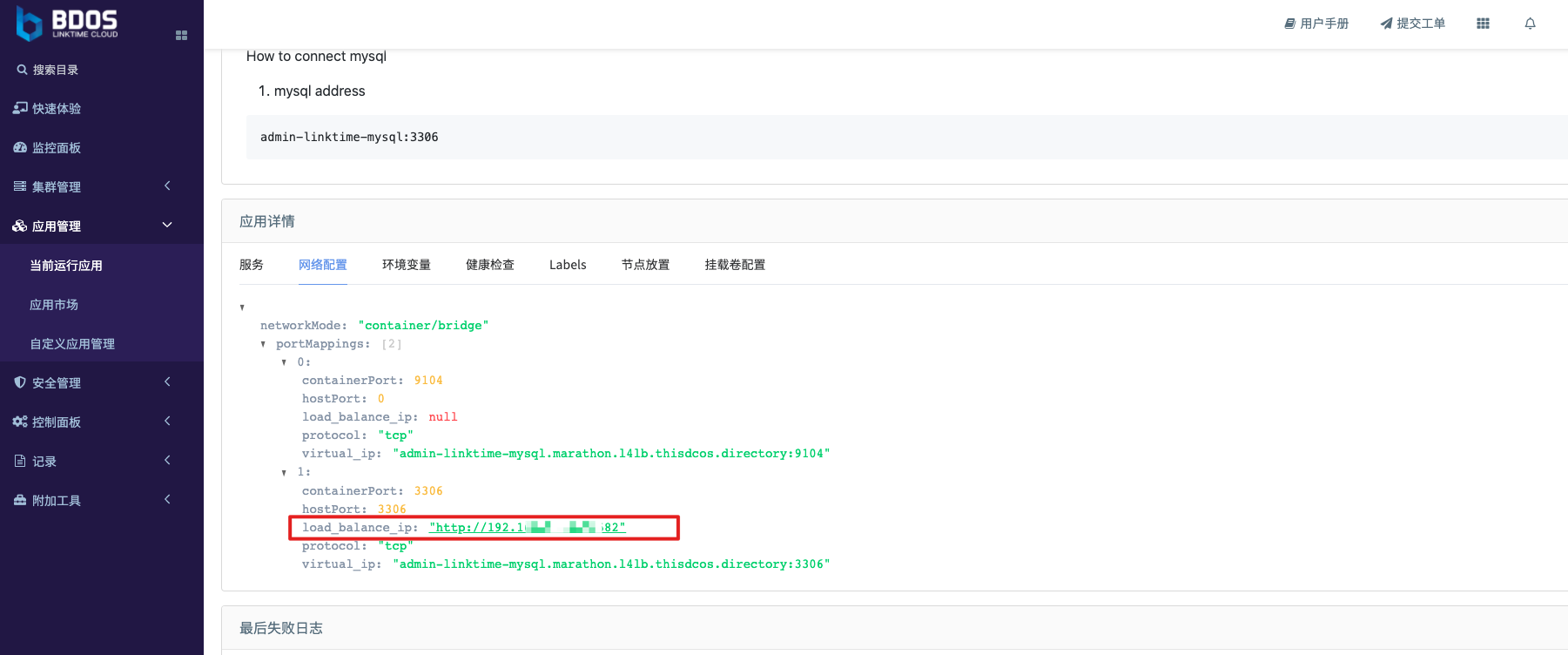
然后,下滑页面至”应用详情” 区域,切换选项卡到”网络配置”,找到附带Mysql的 load_balance_ip
附:load_balance_ip 和 MLB 的解释请参考产品手册的相关章节
step-2: 连接数据库,并导入数据
在获取了数据库的地址后,可以使用任意的数据库连接软件,进行建表和导入数据的操作,本教程使用的 Mysql workbench,使用的 Schema 为 demo (如果没有可以即是创建),然后推荐使用以下建表语句
CREATE TABLE `Iris` (
`sepal_length` float DEFAULT NULL,
`sepal_width` float DEFAULT NULL,
`petal_length` float DEFAULT NULL,
`petal_width` float DEFAULT NULL,
`species` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
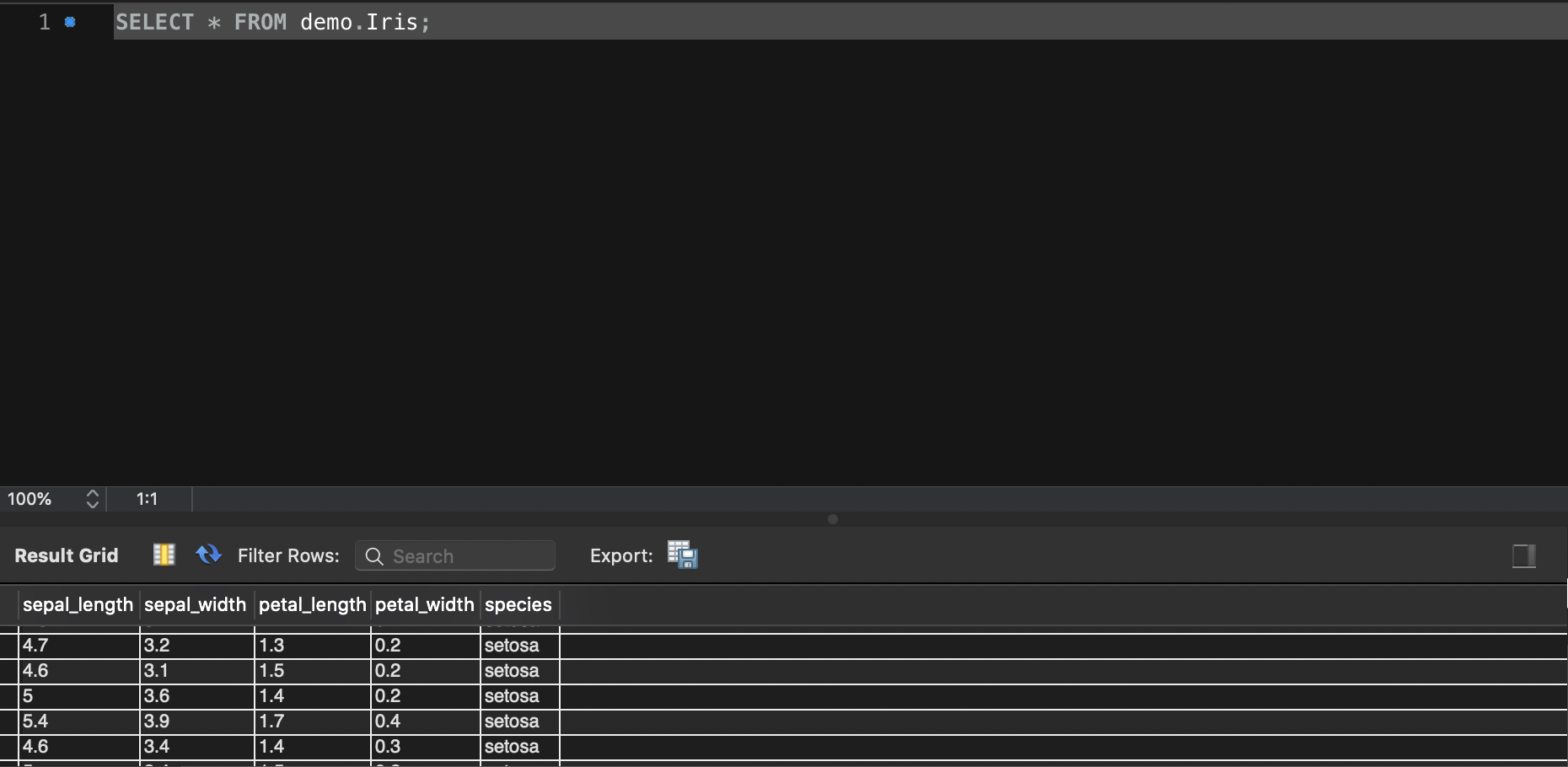
然后导入step1中的样本数据,进行查询之后可以看到以下的结果
step-3: 使用机器学习算法进行模型训练探索
如果用户的机器学习的算法程序已经成熟了,想要直接进行调度训练,可以直接跳至”step4-在FM中使用自定义作业来进行模型调度”
本步骤是机器学习项目的一个标准探索步骤,当企业的数据科学家对算法和样本数据还处于磨合和探索的时候,通常会使用Jupyter进行交互式的模型代码探索和Debug。当算法程序已经打磨成型之后就会创建一个调度的自定义作业来调度训练
集成 Jupyter 是一种推荐选择, BDOS会事先帮助用户集成流行的、常用的大数据组件。用户通过BDOS 云品台特性,可以额外自选其他的类似交互式的组件进行集成使用,具体操作方法可以参照 补充步骤 “supplement-a: 自定义安装一个Jupyter 组件”
登录集群,打开”快速体验”目录,在”快速入口”当中找到 BDOS Jupyter。
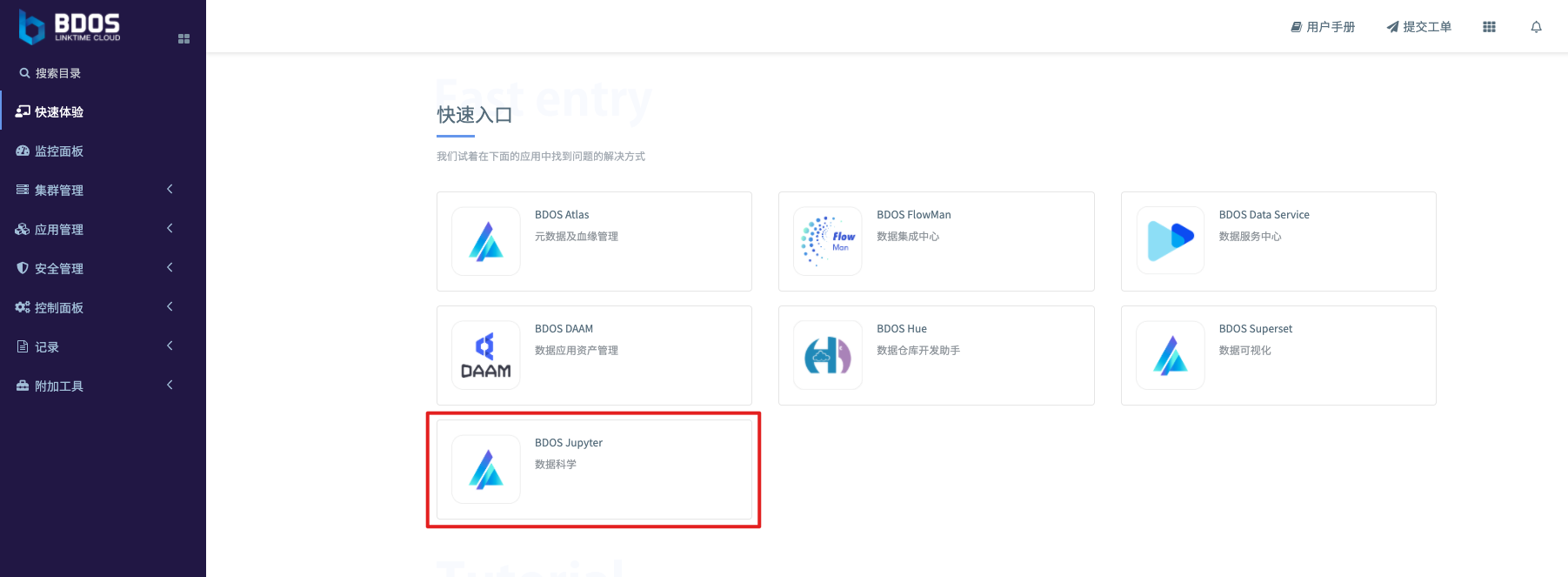

创建一个新的notebook,取名字为 iris

Jupyter 是一个交互式的编程环境,用户每一次的输入都可以得到对应的运行结果,以下会把每一个步骤拆分进行说明
步骤拆分: 接入数据集,并打印查看数据样本
host 和端口使用 step-1 中获取的数值
user 和 password ,初始值请询问进行安装的运维实施人员。实际生产中,客户侧使用BDOS可以自行进行修改
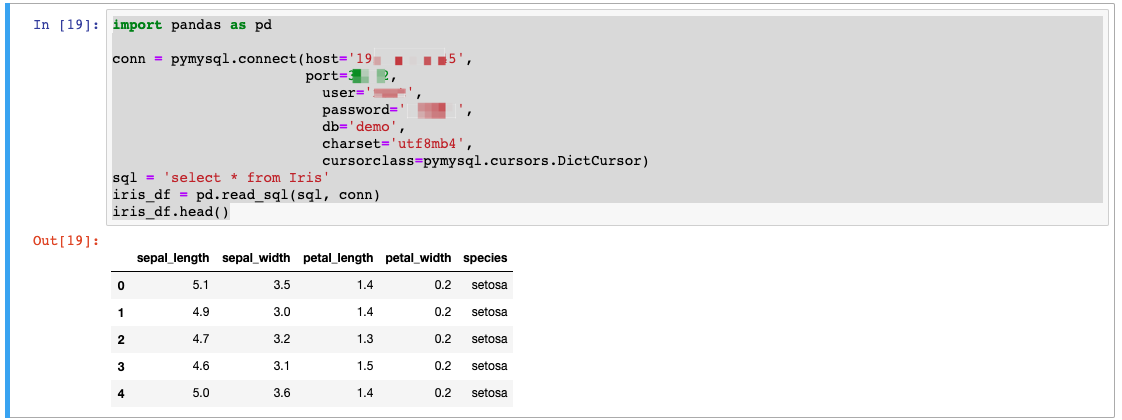
import pandas as pd
conn = pymysql.connect(host='<xxxxx>',
port=<xxxxx>,
user='<xxxx>',
password='<xxxx>',
db='demo',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
sql = 'select * from Iris'
iris_df = pd.read_sql(sql, conn)
iris_df.head()
步骤拆分: 加载机器学习的库,使用决策树进行模型训练
from sklearn.tree import DecisionTreeClassifier
iris_X = iris_df[iris_df.columns.difference(["species"])]
iris_y = iris_df["species"]
dtc = DecisionTreeClassifier()
dtc.fit(iris_X, iris_y)
步骤拆分: 试验一下训练出来的模型,测试一下效果
dtc.predict([[2., 2., 2., 2.]])

这里可以看到,一个新的花,如果是具有以下几个特征
- 花萼长度: 2
- 花萼宽度: 2
- 花瓣长度: 2
- 花瓣宽度: 2
那么模型就会预测,它的种类为 setosa:山鸢尾
步骤拆分: 将训练出来的模型进行导出
import pickle
pickle.dump(dtc, open("irismodel.pkl","wb"))

步骤拆分: 查看导出的模型文件

说明:
- 为了方便下一个步骤 (“step4-封装模型成为一个模型服务” ) 的演示,内置的 BDOS-Jupyter会把文件的挂在卷设置在一个公共的 NFS目录里面,即 不论是 notebook 文件或者是生成的模型都是在共享目录之下。这样其他的程序来调用或者用户直接下载的话都会非常的方便。
- 使用的NFS共享目录为:
/opt/linktimecloud/bdos/admin-jupyter/data,通用的 BDOS 共享目录都会是这个目录结构/opt/linktimecloud/,实际情况可以和负责安装 BDOS 的运维工程师进行核实。(在集群任意节点,都可以访问/opt/linktimecloud/进行查看) - 下一个步骤”step-4-封装模型成为一个模型服务” 和补充步骤”supplement-a: 自定义安装一个Jupyter 组件” 都会讲解如何制定 应用程序的挂载卷配置
第三部分: 发布模型服务
模型训练按成后,需要封装成为一个对外提供服务的接口,以供其他系统来使用。本步骤演示通过发布一个自定义的应用来完成整个过程
step-1: 查看应用发布的程序包
下载以下的程序源码,保存在个人电脑本地
下载:程序包使用的源代码-app.py
下载:程序包使用的源代码-requirement.txt
app.py 源码展示
import pickle
import flask
import os
app = flask.Flask(__name__)
model = pickle.load(open(os.getenv('MODEL_PATH', 'irismodel.pkl'), 'rb'))
@app.route('/predict', methods=['POST'])
def predict():
features = flask.request.get_json(force=True)['features']
prediction = model.predict([features])[0]
response = {'prediction': prediction}
return flask.jsonify(response)
# if __name__ == '__main__':
# app.run()
程序要点解释:
- 程序使用 python flask框架,来构建一个简单的 http 服务用于接口的暴露
- 通过
Model_PATH来指定程序加载机器学习训练出来的模型的路径 - 指定调用方法为
POST,用于构建API路径的的参数为/predict - 通过接受
features的input :即外部给的花萼、花瓣的长宽 - 用于
prediction进行预测,并且进行物种类型的反馈
requirement.txt 文件展示
flask
scikit-learn==0.21.2
文件要点解释:
- 指定主程序需要的的库和包,该场景下需要
flask,和scikit-learn v0.21.2版本这两个
step-2: 使用自定义应用来发布
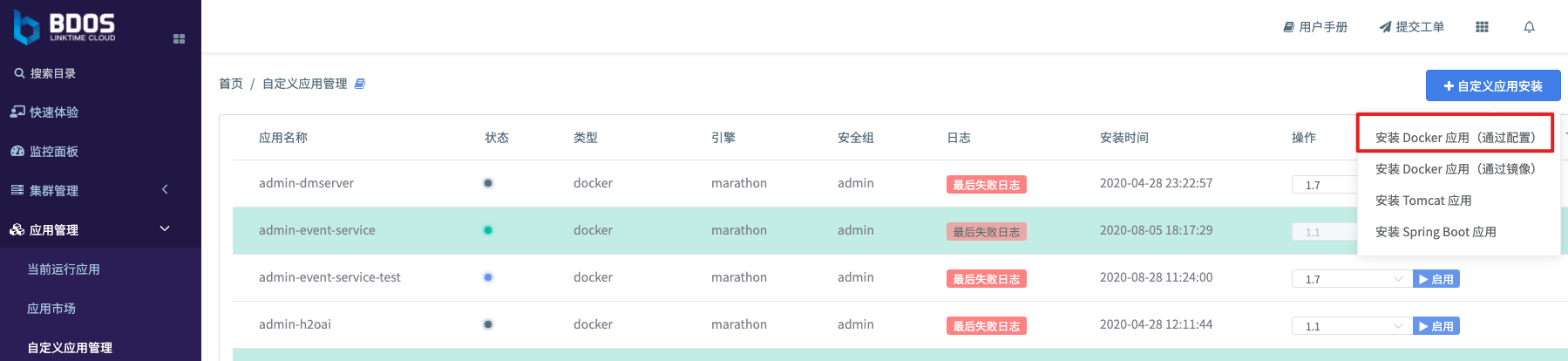
BDOS 云平台部分提供自定义应用发布功能,用户可以使用”安装 Docker 应用(通过配置方式)” 来完成上面程序源码的安装过程。用户登录BDOS之后,打开”应用管理”菜单,点击”自定义应用管理” ,在 “自定义应用安装”之中 选择 安装 Docker 应用(通过配置方式)
整个应用发布的过程,和 “BDOS 教程系列 T1-使用BDOS构建数据驱动服务的闭环”,是一样的,这里不再做通用功能的细节说明,仅对每一个填写项进行说明
填写:基本配置
- 安全组: 选择
admin - 全新安装: 选择
是(对该程序进行跟新发布的时候,则选择否) - 应用名称:
predict-server(如果上一步选择否,那么此步骤则从下拉框中进行选择)

填写: 容器镜像(Docker file)
FROM python:3.6
WORKDIR /usr/src/app
COPY . .
RUN pip install --no-cache-dir -r requirements.txt
ENV FLASK_APP=/usr/src/app/app.py
CMD [ "flask", "run", "--host", "0.0.0.0" ]
要点说明
- FROM: 指定基础镜像,这里的基础镜像是安装了Python 3.6的unix系统
- WORKDIR: 指定容器中的工作目录
- COPY: 拷贝资源文件中的上载文件
- RUN: 运行该行的脚本
- ENV: 指定了flask的启动程序
- CMD: 指定了容器启动时需要运行的命令,即启动flask
填写: 资源文件
- 点击浏览
- 从个人电脑的本地中同时选中和
app.py和requirement.txt - 点击上传

填写: 容器参数
- 保持默认
填写: 网络配置
- 网络模式: 下拉选择 container/bridge
- 点击添加
- 容器端口:
5000 - protocal:
TCP - 负载均衡: 不勾选
- 实际生产中可以勾选上,则可以保持应用重启后不会造成ip/端口的变化
- 这里和客户实际情况是有强关联的,需要管理员统一规划ip和端口,并进行额外设置,在实验中就省略了这一步
- 容器端口:
要点说明
- 容器端口
5000: 5000 是flask的默认端口

填写: 通用配置
- 保持默认 (因为该程序规模不大,可以使用最小的默认配置)
填写: 挂载卷配置
- 点击添加
- container path:
/jupyter/work/ - host path:
/opt/linktimecloud/bdos/admin-jupyter/data/ - Mode: 下拉选择
RO
填写要点说明:
- host path 是 container path 实际在集群的隐射地址,这里因为要使用 “第二部分: 基于python的机器学习程序拆解,训练模型” 的产物,所以需要填写对应的 NFS 共享目录

填写: 环境变量
- 点击添加
- 变量名称:
MODEL_PATH - 变量数值:
/jupyter/work/irismodel.pkl
填写要点说明:
- 这里和 app.py 程序当中的源代码是有对应关系的,可以再次查看step1 的源代码
pickle.load()方法

其余填写可以忽略
在实验教程中,为了简化步骤,关于健康检查、监控以及域名解析部分的配置可以暂时跳过,以下步骤暂时可以忽略
- 健康检查
- 节点放置
- 主页配置
- 监控面板
- 告警配置
step3: 点击安装
- 所有参数填写完毕后, 可以点击”安装”按钮,来启动安装的进程
- 安装成功后,在”自定义应用管理” 列表中,可以看到已经被安装的应用,其使用的应用名为:<安全组名称>-<step2填写的应用名称>
- 然后选择版本(一般为最新的版本),点击启用

step4: 查看程序的运行,获取调用地址
当step3当中的运行成功后, 打开”应用管理”菜单的”当前运行应用”的页面,切换选项卡到 “自定义marathon 应用”,找到刚刚运行的应用 admin-predict-server

点击打开 ,下滑页面到 “运行中的应用实例” ,获取当前运行的实例的ip和端口

说明:
- 在该页面的网络配置中,可以看到
load_balance_ip:null,这里对应的是,step2-填写: 网络配置中,未勾选负载均衡。所以这里的应用实例的 Ip 和端口 会随着每一次应用的重启会有改变,经由集群自动分配 - 实际生产中, 可以根据实际情况进行配置
step5: 得到模型调用的api
在获得了应用的api和端口后,再次查看step1中的程序源码可以看到 /predict', methods=['POST'] 使用 post 方法可以对 http://192.168.7.40:6690/predict 进行调用
第四部分: 使用模型服务
使用api测试工具(本实验使用的是 postman ),使用以下的操作方法(填写后点击send)即可得到模型服务的调用结果
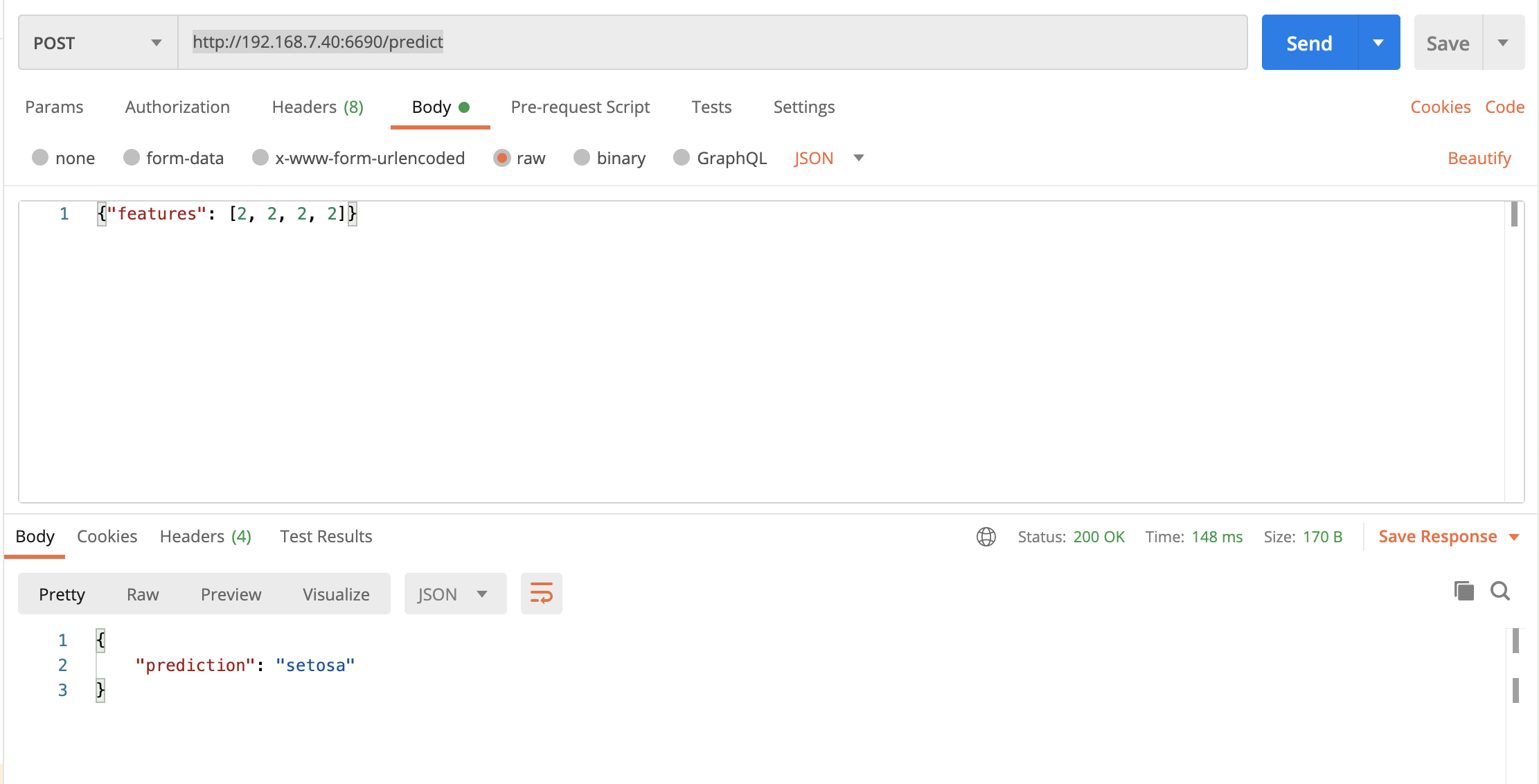
第五部分: 补充步骤
supplement-a: 自定义安装一个Jupyter 应用
BDOS会事先帮助用户集成流行的、常用的大数据分析组件。BDOS 运维实施工程师会根据前期沟通在第一次安装的时候初始化这些组件成为一个系统应用,那么如果,在使用过程中如果发现想要安装其他大数据分析组件 (例如: Jupyter, Zeppline, H20 …) , 并作为一个 自定义应用独立进行维护,应该如何操作? 本步骤的目的就是来进行类似场景步骤拆分演示。
通过步骤拆分可以发现,这个利用 docker 的特性, 这个和安装、发布一般的应用程序是同一个步骤
填写:基本配置
- 安全组: 选择
admin - 全新安装: 选择
是(对该程序进行跟新发布的时候,则选择否) - 应用名称:
self-jupyter(如果上一步选择否,那么此步骤则从下拉框中进行选择)

填写: 容器镜像(Docker file)
# Copyright (c) Jupyter Development Team.
# Distributed under the terms of the Modified BSD License.
FROM jupyter/all-spark-notebook:ad3574d3c5c7
LABEL maintainer="Jupyter Project <jupyter@googlegroups.com>"
# Install Python 3 packages for mysql, hive, papermill, flask, h2o and tensorflow-2.
RUN conda install --quiet --yes \
'pymysql' \
'sasl' \
'impyla' && \
pip install -i https://pypi.doubanio.com/simple/ \
'thrift_sasl==0.2.1' \
'thriftpy2==0.4.0' && \
pip install -i https://pypi.doubanio.com/simple/ --upgrade jupyter_client && \
conda clean --all -f -y && \
fix-permissions $CONDA_DIR && \
fix-permissions /home/$NB_USER
USER root
COPY entrypoint.sh /etc/jupyter/
RUN chmod +x /etc/jupyter/entrypoint.sh
WORKDIR /home/$NB_USER/work
ENTRYPOINT ["/etc/jupyter/entrypoint.sh"]

填写: 资源文件
- 点击浏览
- 从个人电脑的本地中
entrypoint.sh

填写: 容器参数
- 点击添加
- 变量名称:
add-host- 变量值:
hive.linktime.cloud1:1.0.0.11
- 变量值:
- 变量名称:
add-host- 变量值:
hive.linktime.cloud:1.0.0.11
- 变量值:

填写: 网络配置
- 网络模式: 下拉选择 container/bridge
- 点击添加
- 容器端口:
8888 - protocal:
TCP - 负载均衡: 不勾选
- 实际生产中可以勾选上,则可以保持应用重启后不会造成ip/端口的变化
- 这里和客户实际情况是有强关联的,需要管理员统一规划ip和端口,并进行额外设置,在实验中就省略了这一步
- 容器端口:
要点说明
- 容器端口
8888: 8888 是Jupyter的默认端口

填写: 通用配置
- CPU: 0.5
- MEM: 2048
- DISK: 0
- Instance: 1

填写: 挂载卷配置
- 点击添加
- container path:
/home/jovyan/work - host path:
/opt/linktimecloud/bdos/admin-jupyter/data/ - Mode: 下拉选择
RW
- container path:
- 点击添加
- container path:
/keytab - host path:
/home - Mode: 下拉选择
RO
- container path:
- 点击添加
- container path:
/etc/krb5.conf - host path:
/etc/krb5.conf - Mode: 下拉选择
RO
- container path:
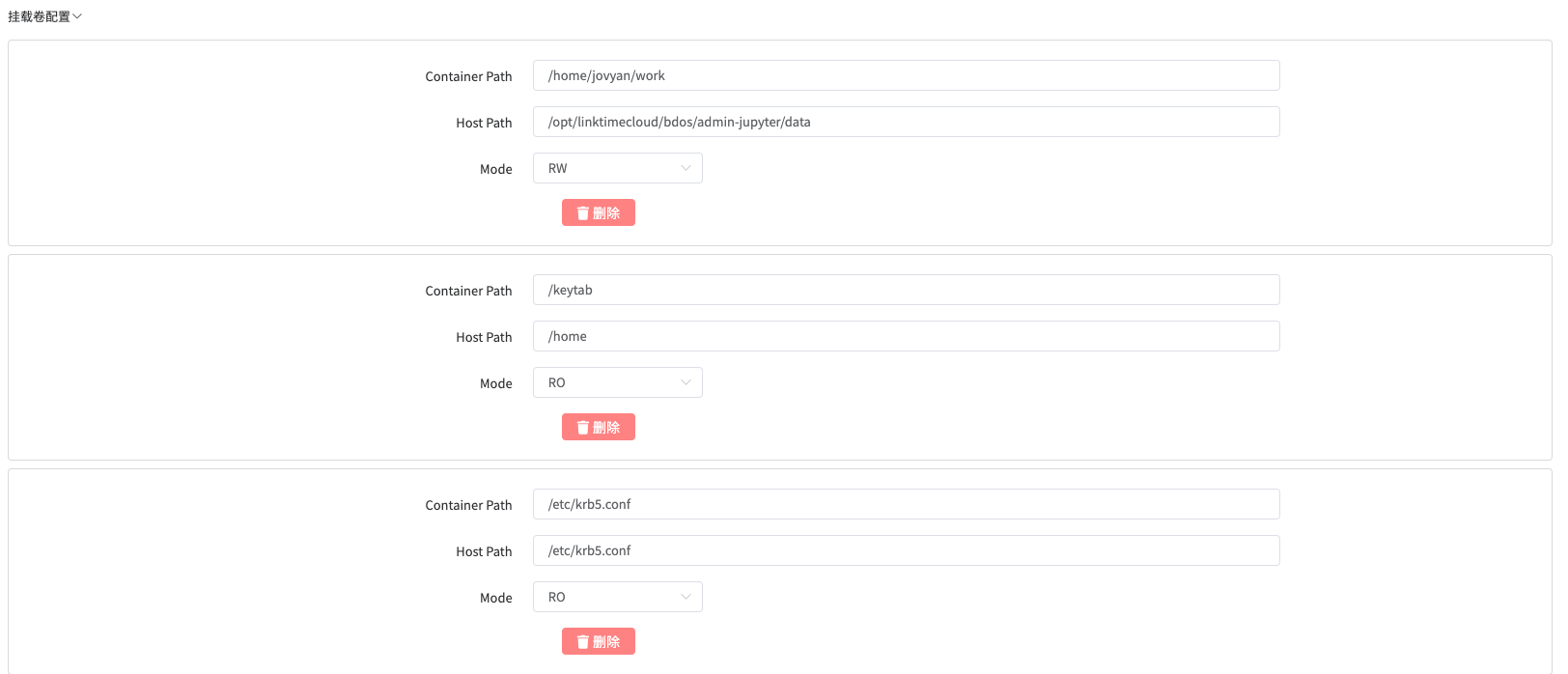
填写: 环境变量
- 点击添加
- 变量名称:
ADMIN_USER - 变量数值:
dcos

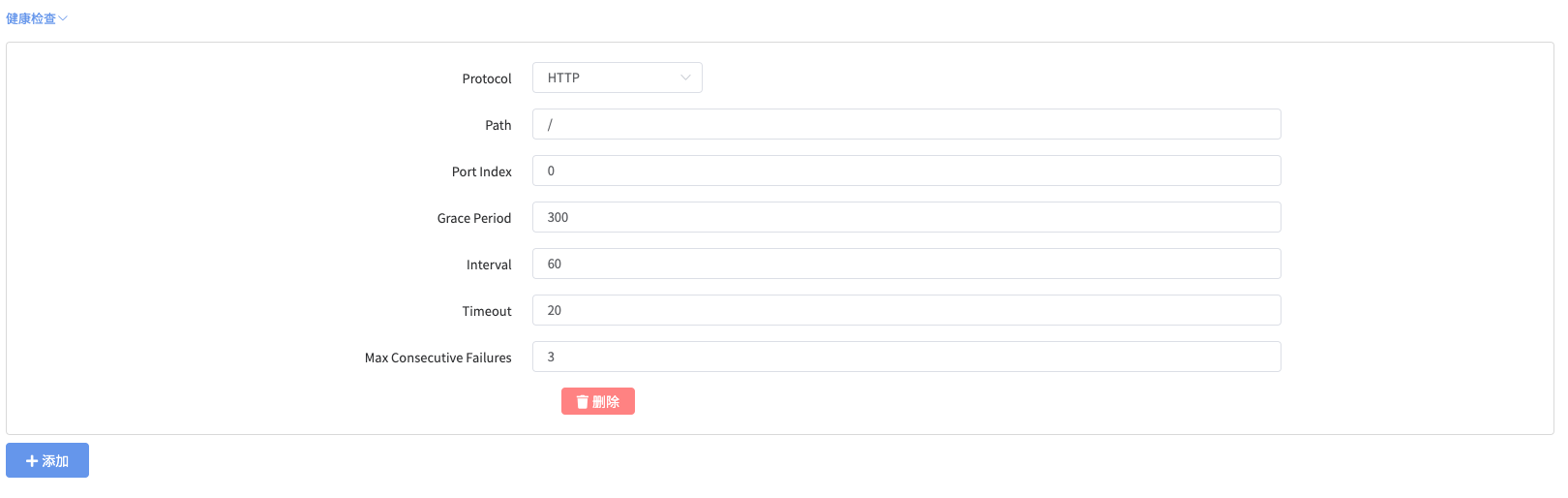
健康检查
- 点击添加
- Protocol:
下拉选择 HTTP - Path:
/ - Port index:
0 - Grace Period:
300 - Interval:
60 - Timeout:
20 - Max Consecutive Failures:
3
其余填写可以忽略
在实验教程中,为了简化步骤,关于健康检查、监控以及域名解析部分的配置可以暂时跳过,以下步骤暂时可以忽略
- 节点放置
- 主页配置
- 监控面板
- 告警配置
安装&发布
- 上述参数都填好之后,点击”安装”
- 安装成功后,点击”启动”
查看运行 & 获得打开地址
打开”应用管理”菜单的”当前运行应用”的页面,切换选项卡到 “自定义marathon 应用”,找到刚刚运行的应用 admin-self-jupyter
击打开 ,下滑页面到 “运行中的应用实例” ,获取当前运行的实例的ip和端口,在浏览器中输入即可开应用主页
supplement-b: 制作一个用于机器学习调度的自定义作业
step1: 制作一个自定义worker来运行机器学习作业
BDOS 相当强大的一个功能在于: 可以即时扩展和安装基于任意场景下的运行环境。例如用户在完成基础的数据仓库构建之后,无需再费神搭建一个机器学习的集群,而是简单的构建一个用于特定目的的 worker 就可以的。所谓的 worker 狭义来理解就是一个容器的环境,所以用户可以按需指定环境,例如:机器学习、TensorFlow,或者是特定爬虫框架,等等。
在这个案例中,就是用这个特定的场景来展示,如何创建一个特定的”自定义worker”。创建一个自定义 worker 由两个大的步骤组成,第一个是在 BDOS-云平台把自定义worker发布成为一个”自定义应用”;第二个是在 BDOS-FM中来把这个发布了的自定义应用作为一个自定义worker进行管理
那么在操作之前,再一次梳理一下”构建自定worker”的目的:
- 其实 BDOS-FM 内置的
basic-etl-worker已经非常强大, 其环境已经涵盖了大部分数据处理的场景 - 但是,因为
basic-etl-worker是专供 FM 的数据处理来使用的,所以其输出并未指定到 NFS 共享目录
- 所以,本步骤一来是演示”如何创建一个自定义worker”;然后是为了真实的对接本实验的实验目的: “用一个调度作业来代替单次运行的交互式 Jupyter” ,需要一个特定的worker将模型输出到指定的共享目录,从而达到稳定而持续的模型更新的场景
- 未来用户可以将模型训练作业前置接入数据处理的工作流水线(参考T2),来构建实际的生产场景。
具体 BDOS-FM 的界面操作, 请参考 BDOS 系列教程-T2: 端到端大数据分析,全面管理数据生命周期
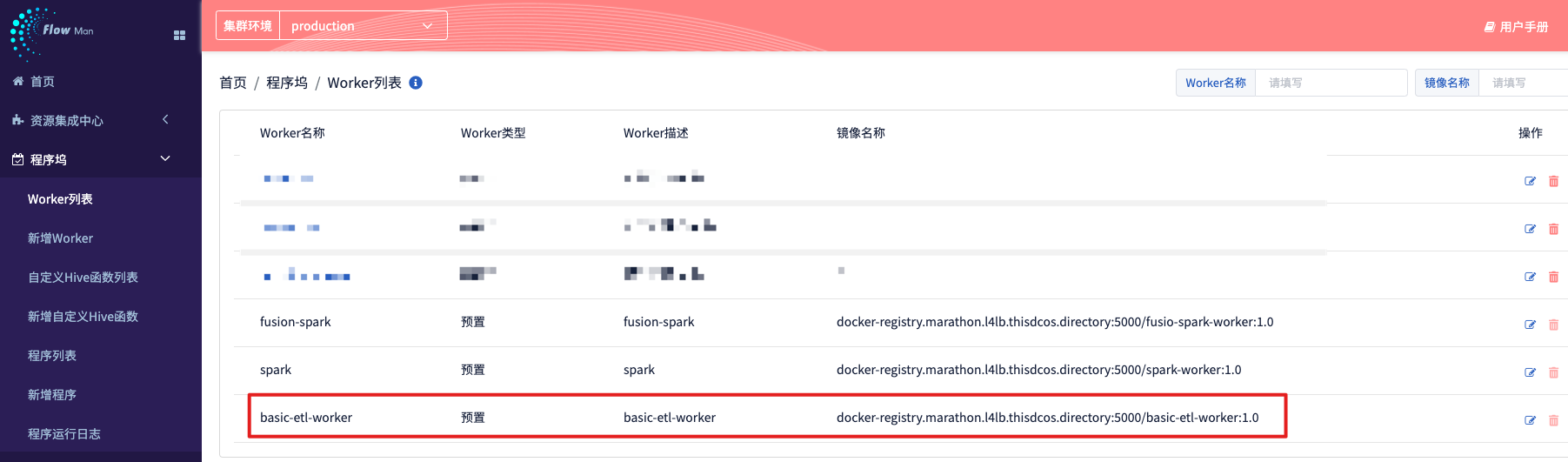
step1.1 在BDOS FM 中创建一个自定义worker获取唯一workerID
登录集群,打开 “快速入口”菜单,在其中找到”FlowMan”, 并打开,随后在 BDOS FM 中打开”程序坞”菜单,点击 “新增worker”,然后填写
- 名称:
machinel-worker - 镜像名称:
* - woker类型: 选择
自定义 - 描述:
机器学习worker
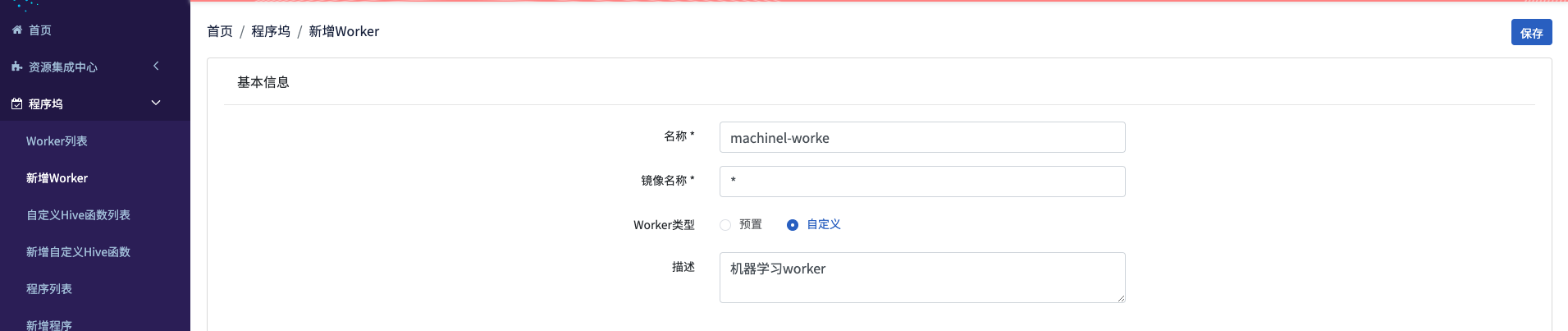
点击保存后,在程序坞-worker列表,可有看见被创建的worker已经存在于列表之中,点击worker名称,进入worker详情页面

在详情页面的 url 中(如图所示),可以获得,该 worker 的唯一 ID,本步骤中 woker的 ID 为9,需要记下这个值,之后给制作 worker 的时候需要通过该ID进行关联。
注: 之后的BDOS 版本会优化worker UID的获取方式
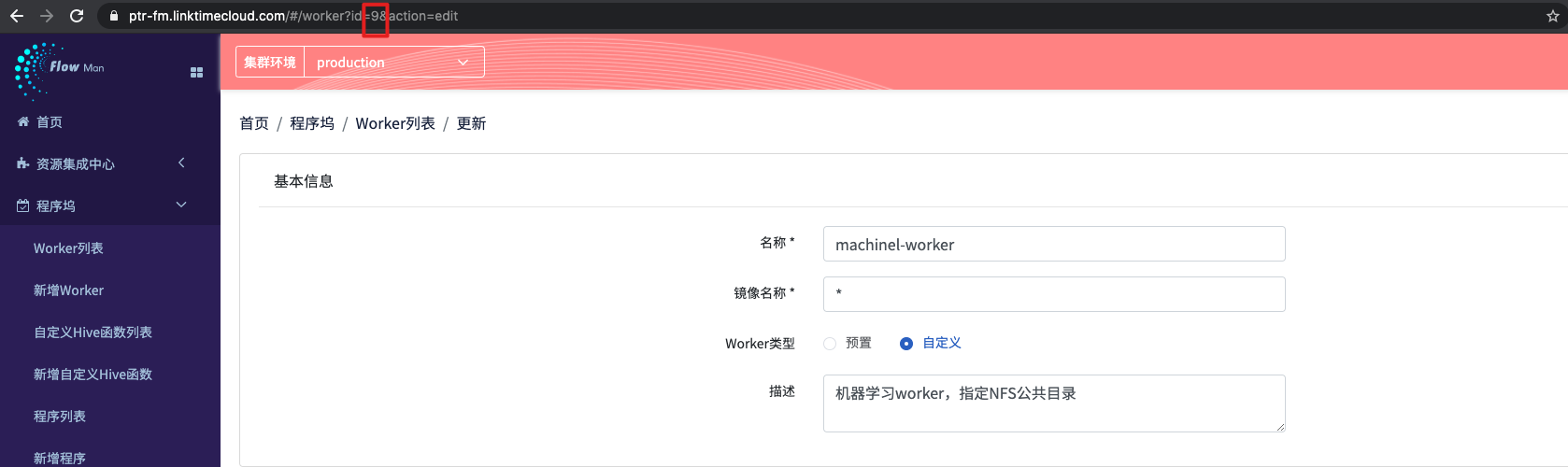
step1.2 在BDOS 云平台 中发布一个自定义应用
所谓的 worker 狭义来理解就是一个容器的环境,即发布一个 docker的应用,所以打开BDOS云平台,打开 “自定义应用安装”
填写:基本配置
- 安全组: 选择
admin - 全新安装: 选择
是(对该程序进行跟新发布的时候,则选择否) - 应用名称:
machinel-worker(如果上一步选择否,那么此步骤则从下拉框中进行选择)
填写:容器镜像
FROM centos:7
MAINTAINER admin@linktime.cloud
COPY CentOS-7.repo.tsinghua /tmp
COPY epel.repo.tsinghua /tmp
COPY RPM-GPG-KEY-EPEL-7 /tmp
RUN mkdir /etc/yum.repos.d/system \
&& mv /tmp/CentOS-7.repo.tsinghua /etc/yum.repos.d/CentOS-Base.repo \
&& mv /tmp/RPM-GPG-KEY-EPEL-7 /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7 \
&& yum clean all \
&& yum install -y curl \
&& yum install -y wget
ADD jdk-8u181-linux-x64.tar.gz /usr/java/
ENV JAVA_HOME /usr/java/jdk1.8.0_181
ENV CLASSPATH $JAVA_HOME/lib;$JAVA_HOME/jre/lib
ENV PATH $PATH:$JAVA_HOME/bin
COPY requirements.txt ./
COPY pip.conf /tmp/pip.conf
RUN yum -y install kde-l10n-Chinese telnet \
&& yum -y install gcc lsof \
&& yum -y reinstall glibc-common \
&& yum -y install https://repo.ius.io/ius-release-el7.rpm \
&& yum clean all \
&& localedef -c -f UTF-8 -i zh_CN zh_CN.utf8 \
&& yum -y install mysql-devel --skip-broken \
&& yum -y install krb5-workstation \
&& yum install -y jq
ENV LC_ALL "zh_CN.UTF-8"
# link python
RUN yum install -y python36u python36u-libs python36u-devel python36u-pip \
&& ln -s /usr/bin/pip3.6 /bin/pip && rm /usr/bin/python && ln -s /usr/bin/python3.6 /usr/bin/python \
&& mkdir -p /root/.pip \
&& mv /tmp/pip.conf /root/.pip/pip.conf \
&& pip install --upgrade pip
RUN pip install -r requirements.txt -i https://pypi.doubanio.com/simple/
ENV WORKDIR_HOME=/schedule.wordir
RUN mkdir -p $WORKDIR_HOME
WORKDIR $WORKDIR_HOME
COPY worker.jar ./
COPY worker.properties.template ./
COPY startWorker.sh ./
LABEL VERSION=0.1
RUN mkdir /data
CMD ["/bin/bash", "startWorker.sh"]
填写:资源文件
下载基于BDOS 3.4.0 的自定义worker 镜像构建资源文件
下载后,解压得到9个文件。界面点击”浏览”然后从个人电脑的本地中同时选中以上9个文件,点击上传
以下是文件说明
- startWorker.sh
- Worker的启动脚本,用户启动worker.jar
- jdk-8u181-linux-x64.tar.gz
- jdk8,且支持java kerberos
- requirements.txt
- python环境下,预安装的依赖库
- 机器学习需要的库都需要放入
- worker.jar
- worker.jar用于和etl-master进行通信
- 重要文件: 和 BDOS 版本号有关联
- CentOS-7.repo.tsinghua
- 镜像加速源,表示安装的这个Docker是CentOS系统,该系统安装系统的各种安装包的时候需要有下载的源
- epel.repo.tsinghua
- 镜像加速源 (不是必须的),这两个.repo文件就是安装包的下载元,都是情怀的官方下载元,这些下载源已经缓存了这些安装包,又是国内的,所以速度会更快
- pip.conf
- pip源配置(不是必须的),是Python在进行install的时候需要用到的pip的配置,通过pip可以给Python提供所需依赖库的下载
- worker.properties.template
- 启动worker.jar包的配置文件,是BDOS平台需要的文件,是平台构建一个自定义worker应用时的一个模板
- RPM-GPG-KEY-EPEL-7
- Linux上的应用主要是实现官方发布的包的签名机制(不是必须的),在下载包的时候使用,可以理解为一个真实身份认证的文件
填写:容器参数
- 保持默认
填写:网络配置
- 保持默认
填写:通用配置
- CPU:
1 - MEM:
1024 - DISK:
0 - Instance:
1
填写:挂载卷配置
- 点击添加
- Container path:
/keytab - Host path:
/home - Mode:
RW
- Container path:
- 点击添加
- Container path:
/etc/krb5.conf - Host path:
/etc/krb5.conf - Mode:
RW
- Container path:
- 点击添加
- Container path:
/data - Host path:
/opt/linktimecloud/bdos/admin-jupyter/data - Mode:
RW
- Container path:
填写:环境变量
- 点击添加
- 变量名:
ADMIN_KEYTAB- 变量值:
/keytab/dcos/dcos.keytab
- 变量值:
- 点击添加
- 变量名:
ADMIN_PRINCIPAL- 变量值:
dcos@LINKTIME.CLOUD
- 变量值:
- 点击添加
- 变量名:
CLIENT_KERBEROS_ENABLED- 变量值:
True
- 变量值:
- 点击添加
- 变量名:
APP_ID- 变量值:
admin-machinel-worker
- 变量值:
- 点击添加
- 变量名:
ETL_SERVICE_ADDRESS- 变量值:
19.8.8.7:9887
- 变量值:
- 点击添加
- 变量名:
MASTER_VIP- 变量值:
19.7.0.2:9702
- 变量值:
- 点击添加
- 变量名:
KERBEROS_ENABLED- 变量值:
True
- 变量值:
- 点击添加
- 变量名:
PARALLEL_NUM- 变量值:
3
- 变量值:
- 点击添加
- 变量名:
WORKER_ID- 变量值:
9
- 变量值:
- 点击添加
- 变量名:
WORKER_LOG_DIR- 变量值:
/root/var/log
- 变量值:
填写:健康检查
- 点击添加
- Protocol:下拉选择
Command - Command:
echo 0 - Grace Period:
300 - Interval:
60 - Timeout:
20 - Max Consecutive Failures:
3
其余填写可以忽略
在实验教程中,为了简化步骤,关于健康检查、监控以及域名解析部分的配置可以暂时跳过,以下步骤暂时可以忽略
- 节点放置
- 主页配置
- 监控面板
- 告警配置
安装&运行
以上配置项都填写完毕后,点击安装,然后点击运行
step2: 将Jupyter notebook 中的代码片段改造成在FM中运行的自定义程序
step2.1: 查看机器学习程序
下载自定义程序 Python 的 irismodeltrain.tgz 模型训练程序包,该程序包可以直击来使用。
这里额外讲解一下,Jupyter notebook 和该程序的对应关系,用户可以作为程序修改的参考。下载解压后可以得到4个程序:
- init.py: 结构文件 (保持不修改)
- run.sh: 启动脚本 (保持不修改)
- baseLogging.py : 日志打印程序 (保持不修改)
- irismodel.py : 主要程序 (需要根据业务来修改,通常名字也要改)
前三个程序是固定模板,第四个程序 irismodel.py 是用户主要需要修改的程序,主要修改以下3个部分,这里可以对照 “第二部分基于python的机器学习程序拆解,训练模型” 的 “step-3: 使用机器学习算法进行模型训练探索” 中每一步的代码片段
第一部分: 添加需要引入的库,查看16-19行,将 jupyter 中使用的库贴入进来

import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import pickle
import pymysql
第二部分: 修改配置信息
查看第 82 – 88,这里是程序需要使用的参数配置,在程序内部可以指定default(默认值),这里推荐的做法是,讲配置参数在程序运行的时候,写在对应作业的自定义配置区域,而不是写在程序内部,因为参数中包含数据库的访问密码,不便于程序的公用

第三部分: 机器学习的核心代码
查看 99 – 111 行代码,在红色区域内,除了用绿色标注出来的,用于打印log的代码之外,其余的部分都是直接从 Jupyter Notebook 拷贝复制进来

注:用户修改了代码之后,需要使用命令tar zcvf irismodel.tgz * 进行重新打包,实际情况需要替换irismodel 这个名字
step2.2: 添加自定义程序
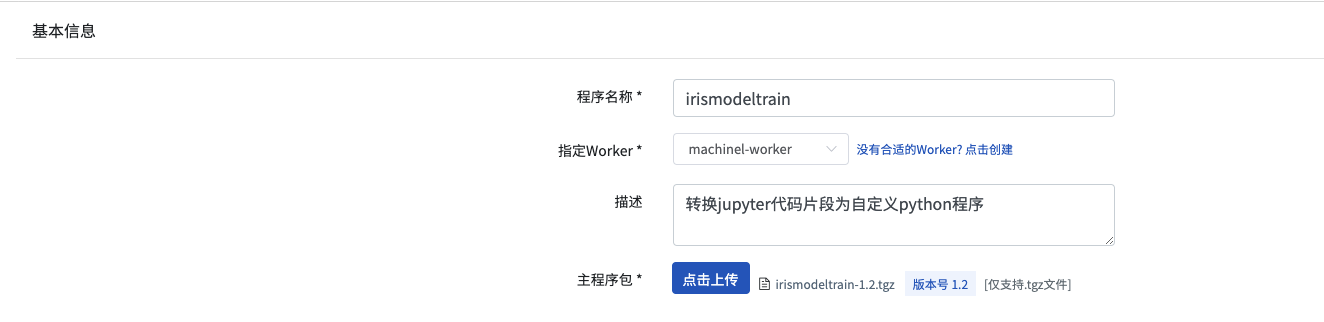
打开BDOS FM,在程序坞菜单,打开新增程序页面,填写
- 程序名称:
irismodeltrain - 指定worker: 下拉选择
machinel-worker(即step1.1 中制作的自定义worker) - 描述:
转换jupyter代码片段为自定义python程序 - 主程序包: 上传
irismodeltrain.tgz - 点击
保存并试运行
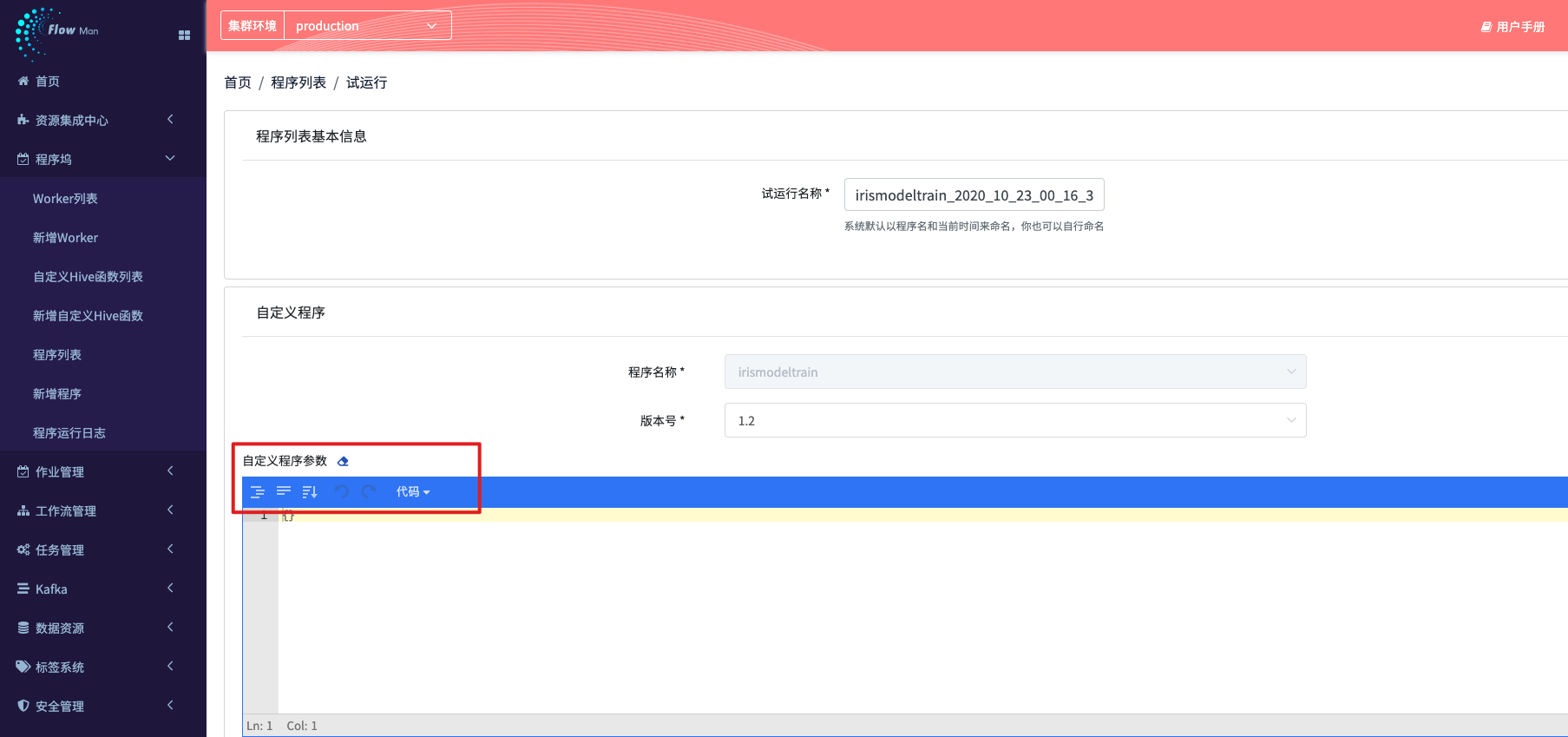
step2.3: 试运行程序
除了从上一步,直接进入试运行界面之外,在程序列表中也可以进入试运行界面。所谓的试运行的用意是,在程序上传后,配合指定的woker 可以尝试运行一次,看一看效果,如果效果好,再转换成为一个正式调度的作业

如果自定义参数不填写, 那么程序运行时候,就会使用程序里面写定的 default的参数值(参考 step2.1 的第二部分)
或者用户可以在这里填写参数,可以让程序更加独立,也便于管理
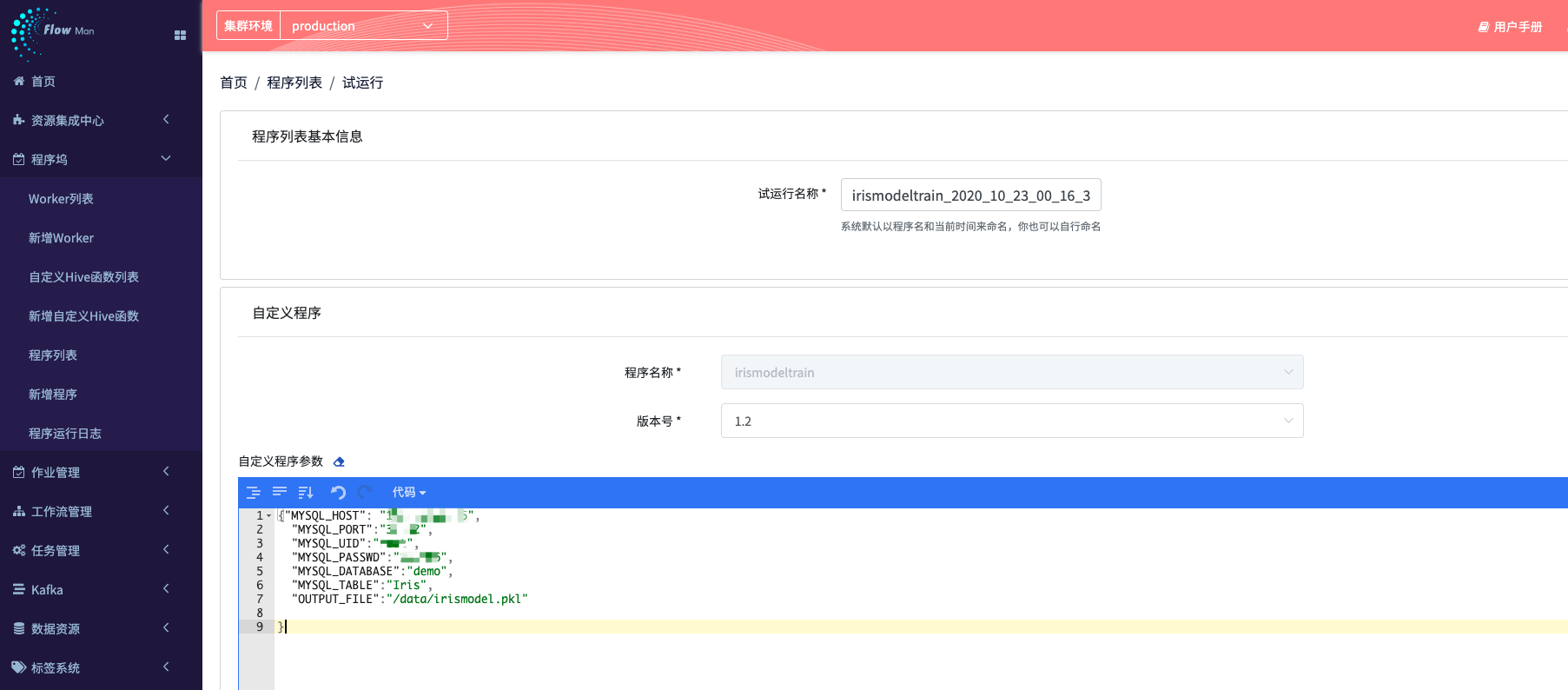
{
"MYSQL_HOST":"xxx",
"MYSQL_DATABASE":"xxx",
"MYSQL_PORT":"xxx",
"MYSQL_UID":"xxx",
"MYSQL_PASSWD":"xxx",
"MYSQL_TABLE":"Iris",
"OUTPUT_FILE":"/data/irismodel.pkl"
}
当准备好之后, 就可以点击 “运行”
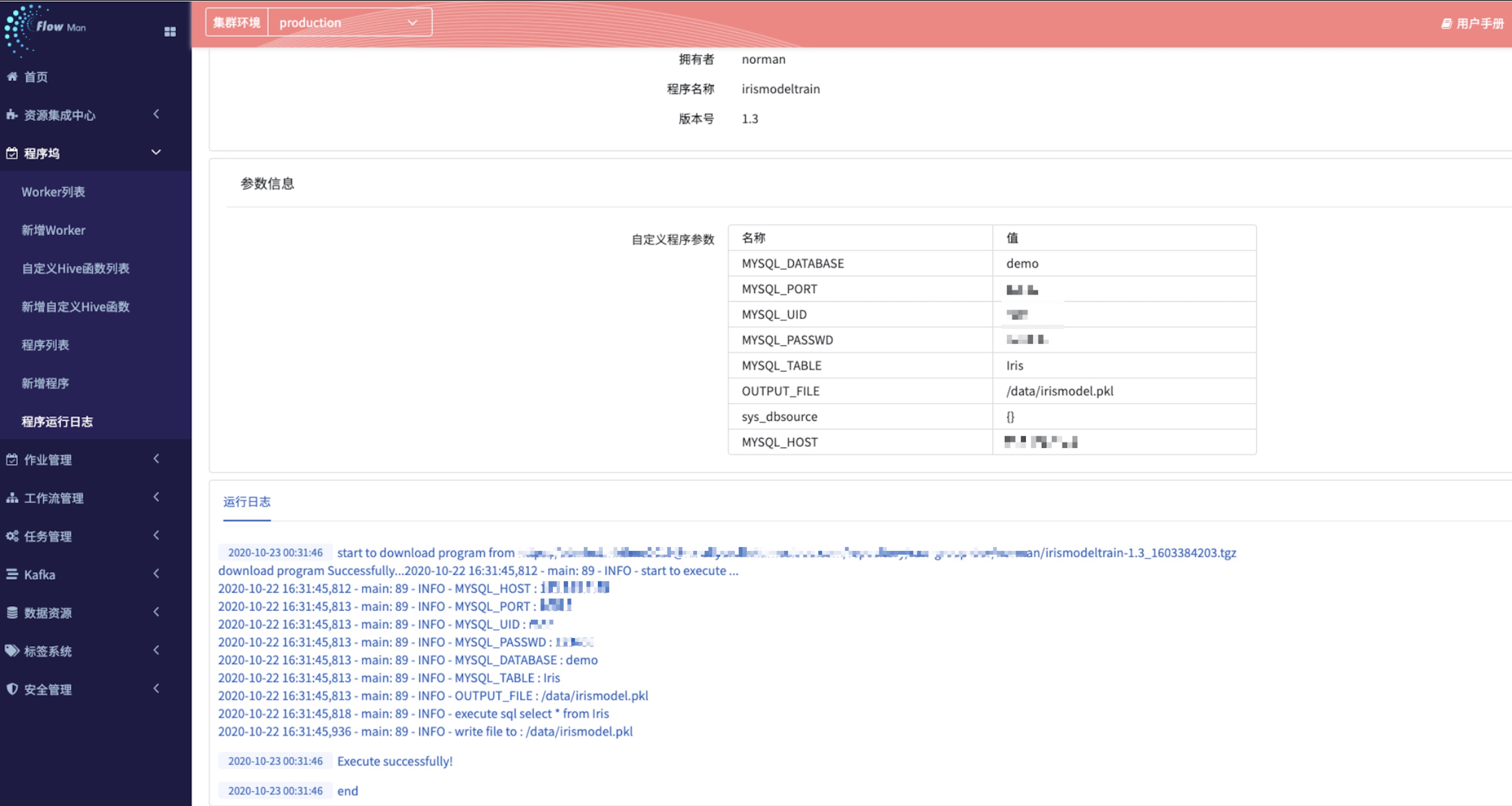
step2.4: 查看模型
此时,机器学习训练的模型就训练好了,用户可以通过以下两种方式来查看模型是否成功生成在指定的共享目录(制作的自定义worker的核心目的之一)
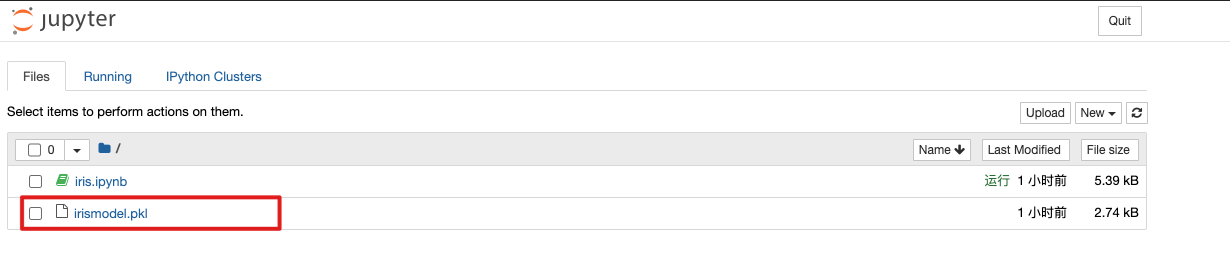
- 打开 Jupyter notebook ,查看是否有最近的模型在目录下生成了 (因为 Jupyter 是链接共享目录的)
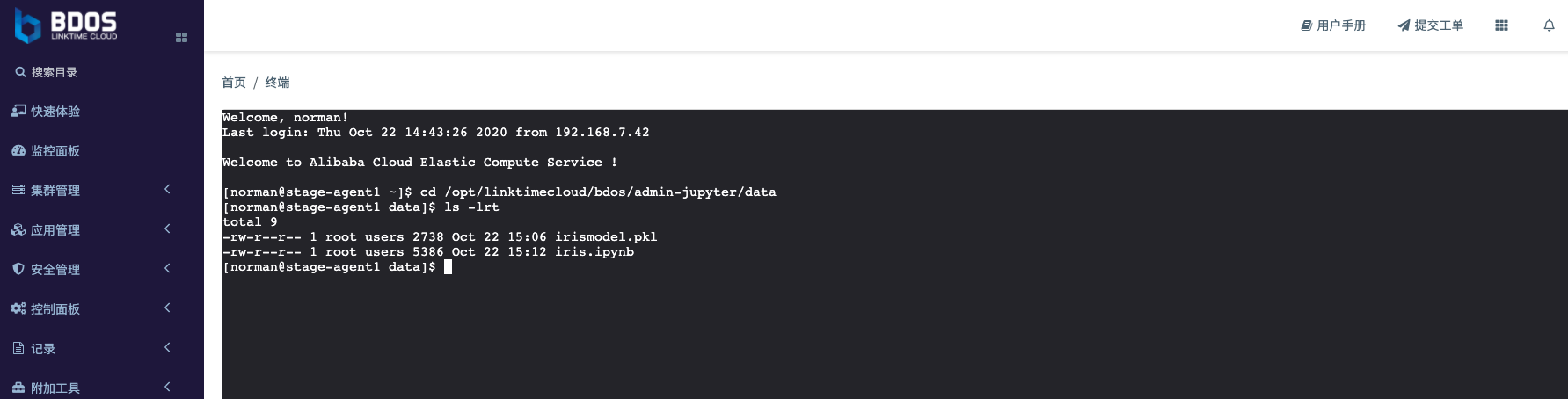
- 或者登陆到任一一台机器,打开共享目录,进行查看
常见问题
程序有区分python2或者python3的版本吗?
* 程序在 python2 的worker 和 python3 的worker 中都有运行过,没有问题
留言
评论
暂时还没有一条评论.