轻松读懂FlashAttention2:更快的注意力,更好的并行性和工作分区
本文由智领云 LeetTools工具自动生成
如果您想试用,请点击链接:https://www.leettools.com/feedback/
在当今人工智能领域,注意力机制的效率和性能至关重要。FlashAttention作为一种新兴的内存高效且快速的注意力机制,已经在标准注意力机制的基础上取得了显著的改进。最新版本FlashAttention-2由Tri Dao引入,目的是进一步加速大型语言模型(LLMs)的训练和推理过程。FlashAttention-2不仅提供了高达4倍的速度提升,还在NVIDIA A100 GPU上实现了72%的模型FLOPs利用率,成为了其前身的理想替代品。
FlashAttention2的基本概念与原理
FlashAttention2是FlashAttention的升级版本,可以提高注意力机制的效率和性能。核心理念是通过优化计算过程和内存使用,显著提升模型训练和推理的速度。FlashAttention2在多个方面相较于标准注意力机制表现出色,特别是在内存效率和计算速度上。
FlashAttention2通过减少非矩阵乘法(non-matmul)浮点运算(FLOPs)的数量来提高效率。研究表明,每个非矩阵乘法FLOP的计算成本是矩阵乘法FLOP的16倍,因此FlashAttention2的设计目标是尽可能多地利用矩阵乘法FLOPs,以保持高吞吐量。这种优化让FlashAttention2在处理长序列时,能够以更低的内存消耗实现更高的计算效率。
FlashAttention2引入了新的特性,如支持高达256的头维度,这比FlashAttention的128头维度有了显著提升。这一改进使得模型如StableDiffusion 1.x、GPT-J等能够在更高的维度上进行计算,实现更快的速度和更优的内存优化。FlashAttention2还支持多查询注意力(multi-query attention)和分组查询注意力(grouped-query attention),这些变体在推理过程中减少了键值缓存的大小,可以显著提高推理性能。
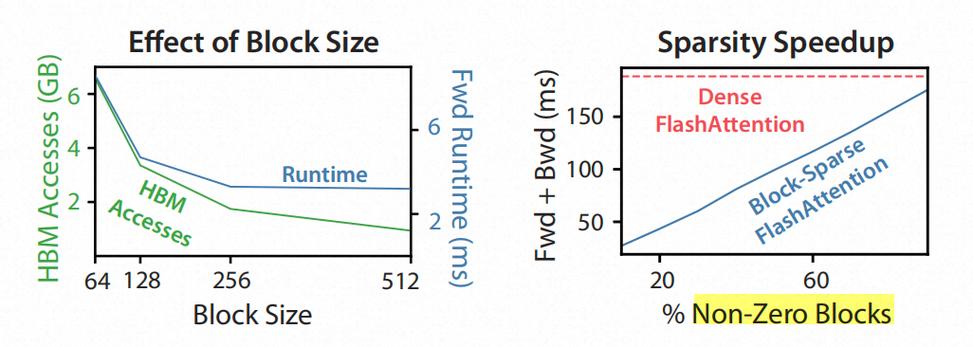
在内存管理方面,FlashAttention2通过更好的工作分配(work partitioning)来减少线程块之间的交互和同步,从而降低了对共享内存的读写操作。具体来说,FlashAttention2在处理大序列时,能够跳过那些所有列索引都大于行索引的块计算,就可以实现约1.7到1.8倍的速度提升。这不仅能提高计算速度,还能减少内存带宽的压力。同时,FlashAttention2的设计充分考虑了GPU的硬件特性,利用NVIDIA的CUTLASS和CuTe库,确保了在不同硬件上都能实现最佳性能。
在并行性方面,FlashAttention2支持批量大小和头数的并行处理。每个注意力头需要一个线程块来处理,整体上需要(batch_size * number of heads)个线程块。为了有效利用GPU的多处理器,FlashAttention2在序列长度维度上进一步并行化,尤其是在处理长序列时,这种方法显著提高了计算效率。通过这些改进,FlashAttention2在前向传播中达到了理论最大吞吐量的50%到73%。
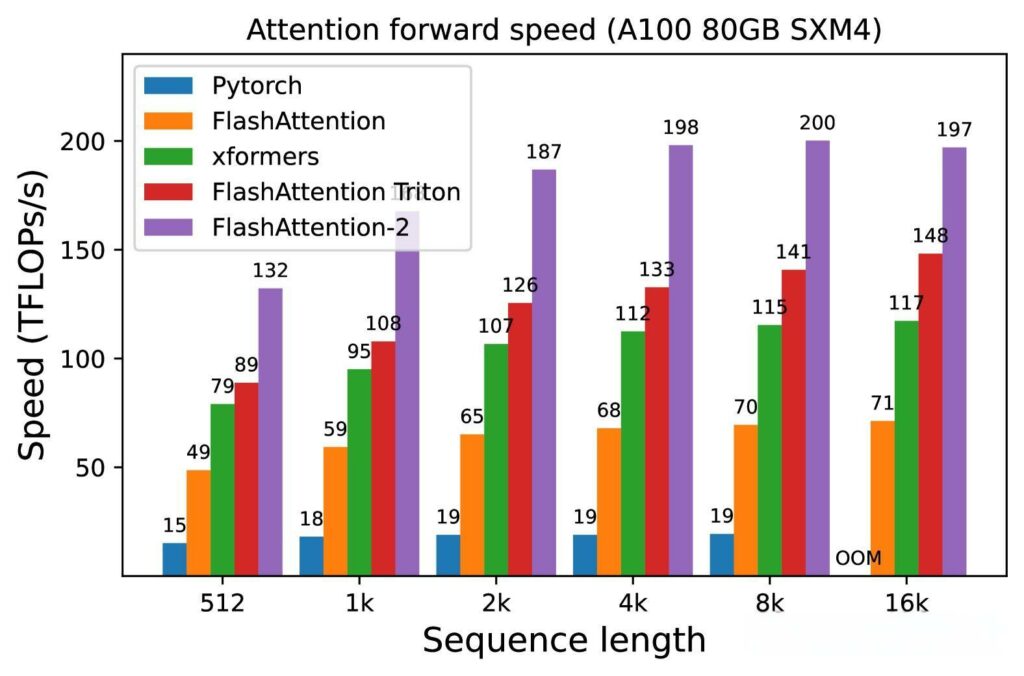
最后,FlashAttention2的实现使得训练速度比FlashAttention快2倍,比标准注意力机制快5到9倍,能够在NVIDIA A100上达到225 TFLOPs/s的训练速度。在相同的计算成本下,能够处理更长的上下文序列,使得在Lambda Cloud等云平台上进行大规模模型训练变得更加可行和经济。通过这些创新,FlashAttention2不仅提升了模型的训练和推理速度,为未来的AI应用奠定了基础。
FlashAttention2在大语言模型中的应用
作为FlashAttention的升级版本,FlashAttention2在核心注意力操作上实现了2倍的速度提升,并在端到端训练Transformer模型时实现了1.3倍的速度提升。这种速度的提升对于大语言模型(LLM)如GPT的训练尤为重要,因为训练这些模型的成本通常高达数百万美元,因此FlashAttention2的引入可能会节省大量资金,并让处理更长的上下文序列成为可能。
FlashAttention2的高效性能可以保证在相同的计算资源下训练更复杂的模型,特别是处理长达16k的上下文时,FlashAttention2的效率会让训练成本与之前8k上下文的模型相当。基准测试结果显示,FlashAttention2在不同设置下(包括有无因果掩码和不同的头维度)都实现了约2倍的速度提升,前向传播的理论最大吞吐量达到了73%,而反向传播则达到了63%。这种高效的计算能力使得FlashAttention2在处理高分辨率视觉、音频数据和视频内容时表现出色,能够显著提高训练、微调和推理的速度。
FlashAttention2通过引入多查询注意力和分组查询注意力等新特性减少了键值缓存的大小,提高了推理性能。通过优化工作分配和并行计算,能够在推理时实现更高的速度和更低的延迟,这对于需要实时响应的应用场景(如对话系统和实时翻译)至关重要。
FlashAttention2的引入不仅可以提升大语言模型的训练和推理速度,还为研究人员提供了更大的灵活性,应对日益增长的计算需求和复杂性。这一技术的进步将推动自然语言处理领域的进一步发展,使得更复杂的模型和应用成为可能。
FlashAttention2的开源与社区支持
FlashAttention2的开源特性使其成为一个极具吸引力的工具,该项目在GitHub上以开源形式发布,用户可以自由访问其源代码并进行修改和扩展。这种开放性不仅促进了技术的透明性,还鼓励了社区的参与和贡献,使得开发者能够在此基础上进行创新和优化。
为了支持用户,FlashAttention2提供了丰富的文档和资源。用户可以在其GitHub页面上找到详细的安装指南、使用示例以及API文档,为新手和经验丰富的开发者提供了必要的支持。另外,FlashAttention2还与Together API集成,用户可以通过该平台进行模型的微调和推理,进一步简化了使用流程。
社区支持方面,开发团队与NVIDIA的CUTLASS团队密切合作,利用其强大的库和工具来优化性能。开发者们也在Discord等社交平台上积极交流,分享经验和解决方案,形成了一个活跃的用户社区。这种社区支持不仅帮助用户解决技术问题,还促进了知识的传播和技术的进步。
FlashAttention2的挑战与用户反馈
尽管FlashAttention2在理论上提供了比其前身FlashAttention更快的训练速度,用户报告的实际体验却并不总是如此。例如,尽管FlashAttention2声称在NVIDIA A100上可以实现225 TFLOPs/s的训练速度,但一些用户发现,在特定的模型和数据集上,实际的训练速度并未达到预期的水平。这种速度的差异可能与用户的硬件配置、模型架构以及数据预处理方式有关。
另外,社区反馈中提到了一些故障排除的困难。用户在尝试优化FlashAttention2的性能时,常常遇到内存不足(OOM)的问题,尤其是在处理长序列时。这种情况使得用户不得不在模型的复杂性和可用内存之间进行权衡,影响了模型的训练效率和效果。尽管FlashAttention2在设计上旨在减少内存读取和写入,但在实际应用中,用户仍然需要仔细管理内存使用,以避免性能瓶颈。
在社区讨论中,用户们分享了他们的经验和解决方案,但由于FlashAttention2的相对新颖性,现有的文档和支持资源可能不足以覆盖所有可能的问题,会导致一些用户在遇到技术障碍时感到孤立无援(在缺乏详细的故障排除指南时)。因此,尽管FlashAttention2在理论上具有显著的性能优势,但用户在实际应用中仍需面对多种挑战,这些挑战可能会影响他们的整体使用体验和模型训练的效率。
留言
评论
暂时还没有一条评论.